

Applies to: Exchange Server 2010 SP3, Exchange Server 2010 SP2
Topic Last Modified: 2012-07-19
High availability strategies for Exchange have focused on the availability and recoverability of data stored in mailbox databases. When you implement a highly available solution for your Mailbox servers, the e-mail messages won't be lost, and they can easily be recovered after a failure, after they arrive in a mailbox.
However, these strategies didn't extend to messages while they're in transit. If a Hub Transport server fails while processing messages and can't be recovered, data loss could occur. As the volume of messages processed by Hub Transport servers increases, potential data loss becomes an increasing concern for administrators.
Microsoft Exchange Server 2007 introduced the transport dumpster feature for the Hub Transport server role. An Exchange 2007 Hub Transport server maintains a queue of messages delivered recently to recipients whose mailboxes are on a clustered mailbox server. When a failover is experienced, the clustered mailbox server automatically requests every Hub Transport server in the Active Directory site to resubmit mail from the transport dumpster queue. This prevents mail from being lost during the time taken for the cluster to fail over. While this does provide a basic level of transport redundancy, it's only available for message delivery in a cluster continuous replication (CCR) environment and doesn't address potential message loss when messages are in transit between Hub Transport and Edge Transport servers.
Exchange Server 2010 introduces the shadow redundancy feature to provide redundancy for messages for the entire time they're in transit. The solution involves a technique similar to the transport dumpster. With shadow redundancy, the deletion of a message from the transport databases is delayed until the transport server verifies that all of the next hops for that message have completed delivery. If any of the next hops fail before reporting back successful delivery, the message is resubmitted for delivery to that next hop.
Shadow redundancy provides the following benefits:
- It eliminates the reliance on the state of any specific Hub
Transport or Edge Transport server. As long as redundant message
paths exist in your routing topology, any transport server becomes
disposable.
- If a transport server fails, you can remove it from production
without emptying its queues or losing messages.
- If you want to upgrade a Hub Transport or Edge Transport
server, you can bring that server offline at any time without the
risk of losing messages.
- It eliminates the need for storage hardware redundancy for
transport servers.
- It consumes less bandwidth than creating duplicate copies of
messages on multiple servers. The only additional network traffic
generated with shadow redundancy is the exchange of discard
status between transport servers. Discard status is the
information each transport server maintains. It indicates when a
message is ready to be discarded from the transport database.
- It provides resilience and simplifies recovery from a transport
server failure.
Shadow redundancy is implemented by extending the SMTP service. The service extensions allow SMTP hosts to negotiate shadow redundancy support and exchange discard status for shadow messages.
Looking for management tasks related to managing transport servers? See Managing Transport Servers.
Shadow Redundancy Components
The following table provides descriptions of all the components of shadow redundancy.
Shadow redundancy components
| Component | Description |
|---|---|
|
Primary message |
The original message submitted to transport for delivery. |
|
Shadow message |
The copy of a message that a transport server retains until it confirms that all the next hops for that message have successfully delivered it. |
|
Primary server |
The transport server that's currently processing a message. |
|
Shadow server |
The transport server that holds shadow copies of a message after delivering the message to the primary server. |
|
Shadow queue |
The queue that a transport server uses to store shadow messages. A transport server will have separate shadow queues for each hop to which it delivered the primary message. |
|
Discard status |
The information a transport server maintains for shadow messages that indicate when a message is ready to be discarded. |
|
Discard notification |
The response a shadow server receives from a primary server indicating a message is ready to be discarded. |
|
Shadow Redundancy Manager |
The transport component that manages shadow redundancy. |
|
Heartbeat |
The process of transport servers verifying the availability of each other. |
Shadow Redundancy Message Flow
To illustrate the mail flow with shadow redundancy enabled, consider the simple scenario where a Hub Transport server sends a message to a third-party mail server via an Edge Transport server in the perimeter network.
Message flow with shadow redundancy
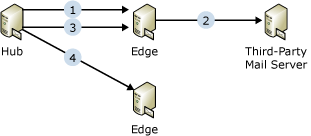
In this scenario, the message flow goes through following stages:
- The Hub Transport server delivers a message to the Edge
Transport server.
- The Hub Transport server opens an SMTP session with the Edge
Transport server.
- The Edge Transport server advertises shadow redundancy
support.
- The Hub Transport server notifies the Edge Transport server to
track discard status.
- The Hub Transport server submits the message to the Edge
Transport server.
- The Edge Transport server acknowledges the receipt of the
message and records the Hub Transport server identity for sending
discard information for the message.
- The Hub Transport server moves the message to the shadow queue
for the Edge Transport server and marks the Edge Transport server
as the primary server. The Hub Transport server becomes the shadow
server.
- The Hub Transport server opens an SMTP session with the Edge
Transport server.
- The Edge Transport server delivers the message to the next
hop.
- The Edge Transport server submits the message to a third-party
mail server.
- The third-party mail server acknowledges the receipt of the
message.
- The Edge Transport server updates the discard status for the
message as delivery complete.
- The Edge Transport server submits the message to a third-party
mail server.
- The Hub Transport server queries the Edge Transport server for
discard status (success case).
- At the end of each SMTP session with the Edge Transport server,
the Hub Transport server queries the Edge Transport server for
discard status on messages previously submitted. If the Hub
Transport server hasn't opened any SMTP sessions with the Edge
Transport server after the initial message submission, it will open
an SMTP session with the Edge Transport server just to query for
the discard status after a specific amount of time.
- The Edge Transport server checks the local discard status and
sends back the list of messages that have been delivered, and
removes the discard information.
- The Hub Transport server deletes the list of messages from its
shadow queue.
- At the end of each SMTP session with the Edge Transport server,
the Hub Transport server queries the Edge Transport server for
discard status on messages previously submitted. If the Hub
Transport server hasn't opened any SMTP sessions with the Edge
Transport server after the initial message submission, it will open
an SMTP session with the Edge Transport server just to query for
the discard status after a specific amount of time.
- The Hub Transport server queries the Edge Transport server for
the discard status and resubmits the message (failure case).
- If the Hub Transport server can't contact the Edge Transport
server, the Hub Transport server resumes the primary server role
and resubmits the messages in the shadow queue.
- Resubmitted messages are delivered to another Edge Transport
server and the workflow starts from stage 1.
 Note:
Note:If there are no alternative routes available for a shadow message (such as the second Edge Transport server shown in the preceding figure), it won't be resubmitted, but remain in the shadow queue.
- If the Hub Transport server can't contact the Edge Transport
server, the Hub Transport server resumes the primary server role
and resubmits the messages in the shadow queue.
For more information about message flow in various different scenarios, see Shadow Redundancy Mail Flow Scenarios.
Multiple Hop Scenario
If a message travels through multiple servers that support shadow redundancy, the shadow messages are retained on a server only until the next server in the message path confirms delivery. To illustrate how this works, consider an organization that has five Active Directory sites with Hub Transport servers installed. The sites are connected to each other as shown in the following figure. The organization has New York and London sites configured as hub sites, so the messages from Chicago or Atlanta need to go through Hub Transport servers in the New York and London sites to get to the Dublin site.
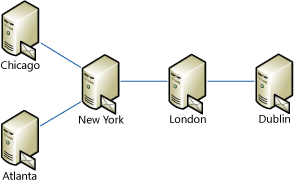
Assume that a message is sent by a user in the Chicago site to a user in the Dublin site. This message will need to travel through the New York and London sites to get to Dublin. In this case, the following occurs:
- The Hub Transport server in Chicago will send the message to
the Hub Transport server in New York, and it will retain a shadow
copy of the message.
- The New York Hub Transport server will send the message to the
Hub Transport server in London and queue a discard status for the
Chicago hub.
- The Chicago hub queries the New York hub for discard status and
receives the discard notification for the message. At this time, it
can remove the shadow message from its database. Whether the
message was delivered from London to Dublin doesn't have an impact
on when the Chicago server deletes the shadow message.
Shadow Redundancy Protection when Hub Transport and Mailbox Server Roles Coexist with DAGs
When using database availability groups (DAGs), the messages that are already committed to mailbox databases are protected with the DAG architecture. For any message delivered to a mailbox database that's part of a DAG, the shadow copy for that message is retained in the transport dumpster until that message is replicated to all DAG members. Similarly, any message submitted to Hub Transport servers from a DAG member has two copies, one in the Hub Transport server queue waiting for delivery, and a shadow copy in the sender's Sent Items folder. This approach is a key component of shadow redundancy.
However, when the Hub Transport and Mailbox server roles coexist on the same server, and you have mailbox databases that are part of a DAG, Hub Transport servers may have to route a message through an extra hop to avoid having the primary message and the shadow message on the same server hardware. Specifically, the Hub Transport server role attempts to avoid the following two scenarios because a failure of a single server may result in the loss of both the primary and shadow messages:
- During message delivery, where the active mailbox database
of the message recipient and the transport dumpster containing the
shadow copy of the message are on the same
server To avoid this scenario, the Hub
Transport server routes the message through another Hub Transport
server within the site to ensure that the shadow message ends up on
different server hardware. However, if no other Hub Transport
servers are available, it delivers the message directly.
- During message submission, where the transport queue holding
the primary message and the shadow message in the Sent Items folder
of the sender are on the same server To avoid
this scenario, the store driver prefers other Hub Transport servers
in the site for message submission. However, if no other Hub
Transport servers are available in the site, it submits the message
to the local Hub Transport server.
For more information about Hub Transport and Mailbox server role coexistence when using DAGs, see Hub Transport and Mailbox Server Roles Coexistence When Using DAGs.
Interoperability
Whether shadow redundancy will be used or not is decided while establishing a new SMTP connection. If both servers in an SMTP connection support shadow redundancy, the workflow mentioned previously is used. However, there will be situations where Exchange 2010 transport servers exchange messages with mail servers that don't support shadow redundancy. These could be third-party mail servers, earlier versions of Exchange, or an Exchange 2010 organization that hasn't enabled shadow redundancy.
When an Exchange 2010 transport server that supports shadow redundancy establishes a connection with a server that doesn't support shadow redundancy, the following events take place:
- Exchange establishes an SMTP connection to the target
server.
- The target server doesn't advertise shadow redundancy
support.
- Because the target server doesn't support redundancy, Exchange
will perform the following for each message:
- Deliver the message to the target server.
- Shadow Redundancy Manager will mark that the message is
delivered to the next hop.
- Delete the message after it's delivered to all of the next
hops.
- Deliver the message to the target server.
When a server that doesn't support shadow redundancy establishes a connection with an Exchange 2010 server, the following events take place:
- The sending server establishes an SMTP connection with
Exchange.
- Exchange advertises shadow redundancy support.
- The sending server doesn't support shadow redundancy and
therefore it won't use it. It will deliver messages to the Exchange
server.
- For each message Exchange receives, it will do the
following:
- Deliver the message to the next hop, or make a shadow copy of
it.
- Send acknowledgement to the sending server.
- Deliver the message to the next hop, or make a shadow copy of
it.
Delayed Acknowledgement
The main principle behind shadow redundancy is maintaining a copy of the message on the previous hop until the server verifies that it has successfully delivered it to all the next hops. This isn't possible when an Exchange 2010 transport server is receiving a message from a mail server that doesn't support shadow redundancy. This mail server can be an Exchange server running an older version of Exchange, a standard SMTP client, or a non-Exchange mail server on the Internet. In this case, Exchange attempts to achieve shadow redundancy by delaying the acknowledgement to the mail server until it verifies that the message has been successfully delivered to all the next hops internally. This way, if the Exchange 2010 server fails, the sending mail server will assume that the message was never delivered to Exchange and will attempt delivery again.
However, the delivery of the message to the next hops may take a long time due to the complexity of your routing infrastructure, or failure of one of the next hops. In this case, to prevent the SMTP session from timing out, the Exchange 2010 transport server will send an acknowledgement to the sending mail server. In this case, the mail redundancy isn't guaranteed, but it's a best effort. For example, a message may be lost in the following scenario: An Internet mail server transmits a message to an Edge Transport server. The Edge Transport server can't communicate with the Hub Transport server due to a network problem and acknowledges the receipt of the message to the Internet mail server. The Edge Transport server then fails and can't be recovered before the network problem is resolved. At this point, the message is lost.
The delayed acknowledgement time-out value is controlled by the MaxAcknowledgementDelay attribute of each Receive connector. The default value is 30 seconds. To learn more about configuring this attribute, see Configure Shadow Redundancy.
Bypassing Delayed Acknowledgement
There are cases where it's unlikely a message will be delivered before the delayed acknowledgement time-out is reached. In these cases, the transport server uses one of the following methods to handle messages:
- Skipping delayed acknowledgement By
default, the transport server skips the delayed acknowledgement to
maintain SMTP receive throughput. In essence, the transport server
issues an acknowledgment before the time-out is reached.
- Shadow redundancy promotion In
Microsoft Exchange Server 2010 Service Pack 1 (SP1), instead
of skipping the delayed acknowledgement, the transport server can
be configured to relay the message to any other transport server in
the site. This effectively inserts the message into the shadow
redundancy pipeline, thereby protecting the message. This process
is called shadow redundancy promotion. This approach
minimizes the number of unprotected messages in the organization
when compared to the skipping delayed acknowledgement method. By
default, this feature is disabled. To enable shadow redundancy
promotion, an administrator must edit the Edgetransport.exe.config
file, change the shadowredundancypromotionenabled key to
true, save the changes to the file, and then restart the
Microsoft Exchange Transport service (MSExchangeTransport.exe). For
more information about how to do this, see the “Enable Shadow
Redundancy Promotion“ section in the Configure Shadow
Redundancy topic.
The following table lists different scenarios ion which a transport server bypasses delayed acknowledgement, and describes how an Exchange 2010 server handles that scenario.
| Scenario | Exchange 2010 default behavior (skipping delayed acknowledgement) | Exchange 2010 SP1 with shadow redundancy promotion enabled |
|---|---|---|
|
The target queue for the message is either in suspended or retry state. |
The receiving transport server skips the delayed acknowledgement. |
The receiving transport server immediately uses shadow redundancy promotion. |
|
The target queue enters retry state after the message is added to it. |
The receiving transport server skips the delayed acknowledgement for subsequent messages until the target queue returns to ready state. |
The receiving transport server uses shadow redundancy promotion for subsequent messages until the target queue returns to ready state. |
|
An administrator suspends either the target queue or the message. |
If the administrator suspends the target queue, the receiving transport server skips the delayed acknowledgement until the target queue returns to ready state. If the administrator suspends the message, the receiving transport server handles subsequent messages normally. |
If the administrator suspends the target queue, the receiving transport server uses shadow redundancy promotion until the target queue returns to ready state. If the administrator suspends the message, the receiving transport server handles subsequent messages normally. |
|
The target queue for the message has more than 100 messages. |
The receiving transport server skips the delayed acknowledgement until the target queue size falls below 100. |
If the target queue has any messages in it, the receiving transport server uses shadow redundancy promotion for subsequent messages until the queue clears. |
Shadow Redundancy Manager
Shadow Redundancy Manager is the core component of an Exchange 2010 transport server that's responsible for managing shadow redundancy.
Shadow Redundancy Manager is responsible for maintaining the following information for all the primary messages that a server is currently processing:
- The shadow server for each primary message being processed.
- The discard status to be sent to shadow servers.
Shadow Redundancy Manager is responsible for the following for all the shadow messages that a server has in its shadow queues:
- Maintaining the list of primary servers for each shadow
message.
- Checking the availability of each primary server for which a
shadow message is queued.
- Processing discard notifications from primary servers.
- Removing the shadow messages from the database after all
expected discard notifications are received.
- Deciding when the shadow server should take ownership of shadow
messages, becoming a primary server.
In addition, Shadow Redundancy Manager is also responsible for managing performance counters related to shadow redundancy.
Heartbeat
Shadow Redundancy Manager uses heartbeat to determine the availability of the servers for which shadow messages are queued. During the SMTP session between two servers that both support shadow redundancy, the server that initiates the connection queries the target server for discard status of messages previously submitted to that server. The initiating server accomplishes this by issuing an XQUERYDISCARD command. In response, the target server returns the discard notifications. This exchange between the two servers is used as the heartbeat for shadow redundancy.
There is a time-out value for the heartbeat. If no connections are established to a server for which Shadow Redundancy Manager is maintaining a shadow queue for that duration, the server will attempt to establish an SMTP connection with the primary server specifically to query the discard status and reset the timer. The time-out value is controlled by the ShadowHeartbeatTimeoutInterval parameter of the Set-TransportConfig cmdlet. The default value for this parameter is 300 seconds in the release to manufacture (RTM) version of Exchange 2010, and 900 seconds in Exchange 2010 SP1.
If the server can't establish a connection to a primary server when the time-out value is reached, it will reset the timer and try again. If the time-out value is reached twelve times in a row (three times in a row in Exchange 2010 RTM), the server will conclude that the primary server has failed and will assume ownership of the shadow messages and begin to generate discard notifications for them to send to the primary server that failed. The number of time-outs a server will wait before deciding a primary server has failed is controlled by the ShadowHeartbeatRetryCount parameter of the Set-TransportConfig cmdlet.
To learn more about configuring the shadow redundancy heartbeat, see Configure Shadow Redundancy.
Message Processing After an Outage
Shadow redundancy minimizes message loss due to server outages. When a transport server comes back online after an outage, there are two scenarios:
- The server comes back online with a new transport
database In this scenario, the transport
database is unrecoverable due to data corruption or hardware
failure. In this case, because the transport server will have a new
database ID, it will be recognized as a new route by the other
transport servers in the organization. This also applies to the
situation where a server couldn't be recovered, and a new server
was provisioned as a replacement.
- The server comes back online with the same transport
database In this scenario, the particular
transport server didn't fail, but was offline for an extended
period of time. For example, a network card failure, or a long
maintenance on the server would cause this scenario.
The following table summarizes how transport reacts to these two scenarios when shadow redundancy is enabled. For clarity, assume that the server that had an outage is named Hub01.
Message processing in recovery scenarios
| Recovery scenario | Actions taken for messages that have alternative routes | Actions taken for messages with no alternative routes |
|---|---|---|
|
Hub01 comes back online with a new database. |
When Hub01 becomes unavailable, each server that has shadow messages queued for Hub01 will assume ownership of those messages and resubmit them. The messages then get delivered to their destinations using alternative routes. The total delay for messages is equal to the product of the heartbeat time-out interval and the heartbeat retry count configured in your organization. |
These messages remain in the shadow queue on each server that has shadow messages queued for Hub01. When Hub01 comes back online with a new database ID, the shadow servers detect that it's a new database and resubmit the messages that are in the shadow queue to Hub01. This is equivalent to suddenly discovering an alternative route for these messages. The total delay for the messages depends on the duration of the outage. |
|
Hub01 comes back online with the same database. |
Hub01 will deliver the messages in its queues. This will result in duplicate delivery of these messages. Exchange mailbox users won't see duplicate messages due to duplicate message detection. However, recipients on foreign systems may receive duplicate copies. The total delay for messages is equal to the product of the heartbeat time-out interval and the heartbeat retry count configured in your organization. |
Hub 01 will deliver the messages in its queues and then send discard notifications to the shadow servers. The total delay for the messages depends on the duration of the outage. |
Extended Rights Required for Shadow Redundancy
Exchange 2010 introduces the following two extended rights, which are required for shadow redundancy:
- ms-Exch-SMTP-Accept-XSHADOW
- ms-Exch-SMTP-Send-XSHADOW
When an SMTP connection is established to an Exchange 2010 transport server, it will advertise shadow redundancy support if the ms-Exch-SMTP-Accept-XSHADOW extended right exists on the Receive connector being used. In addition, the authentication mechanism on the Receive connector should be either Exchange Server authentication or Externally Secured.
When an Exchange 2010 transport server establishes an SMTP connection to another server that advertises shadow redundancy support, it will issue an XSHADOW command only if the session has been granted the ms-Exch-SMTP-Send-XSHADOW extended right.
By default, these extended rights are granted to the Exchange Servers group on all internal Send connectors and Receive connectors.
| Note: |
|---|
| Shadow redundancy can be enabled or disabled for the entire organization using the ShadowRedundancyEnabled parameter of the Set-TransportConfig cmdlet. This setting overrides the extended rights described in this section. If shadow redundancy is disabled for the organization, Exchange will never advertise shadow redundancy support or issue XSHADOW commands even if the necessary extended rights are granted to the SMTP session. |