

Applies to: Exchange Server 2013
Topic Last Modified: 2012-11-16
Making sure that servers are operating reliably and that database copies are healthy are key daily objectives for messaging administrators. To help ensure the availability and reliability of your Microsoft Exchange Server 2013 organization, the hardware, Windows operating system, and Exchange 2013 services and protocols must be actively monitored.
Historically, monitoring Exchange has meant using an external application, such as System Center 2012 Operations Manager, to collect performance and event log data, and to react or provide recovery action for problems that are detected as a result of analyzing the collected data. Exchange 2010 and previous versions included health manifests and correlation engines in the form of management packs. These correlation engines would analyze the collected data and make a determination as to whether a particular component was healthy or unhealthy. In addition, System Center 2012 Operations Manager was also able to leverage the built-in test cmdlet infrastructure to run synthetic transactions against various aspects of the system to ensure the system was available.
In Exchange 2013, native, built-in monitoring and recovery actions are included in a feature called Managed Availability.
You can use the details in this topic for monitoring the health and status of mailbox database copies for database availability groups (DAGs).
Contents
Get-MailboxDatabaseCopyStatus cmdlet
CollectReplicationMetrics.ps1 script
Managed availability
Managed availability is the integration of built-in monitoring and recovery actions with the Exchange built-in high availability platform. It's designed to detect and recover from problems as soon as they occur and are discovered by the system. Unlike previous external monitoring solutions for Exchange, managed availability doesn't try to identify or communicate the root cause of an issue. It's instead focused on recovery aspects that address three key areas of the user experience:
- Availability Can users access the
service?
- Latency How is the experience for
users?
- Errors Are users able to accomplish
what they want?
The new architecture in Exchange 2013 makes each Exchange server an island where services on that island only service the active databases located on that server. The architectural changes in Exchange 2013 require a new approach to availability model used by Exchange. The Mailbox and Client Access server architecture imply that any Mailbox server with an active database is in production for all services, including all protocol services. As a result, this fundamentally changes the model used to manage the protocol services.
Managed availability was conceived to address this change and to provide a native health monitoring and recovery solution. The integration of the building block architecture into a unified framework provides a powerful capability to detect failures and recover from them. Managed availability moves away from monitoring individual separate slices of the system to monitoring the end-to-end user experience, and protecting the end user's experience through recovery-oriented computing.
In Exchange 2013, client access protocols for a specific mailbox are always served from the protocol instance that's local to the active database copy. As a result, it's important that managed availability's monitoring and recovery actions take into account more than just the health of the database.
Managed availability is an internal process that runs on every Exchange 2013 server. It's implemented in the form of two services:
- Exchange Health Manager Service
(MSExchangeHMHost.exe) This is a controller
process used to manage worker processes. It's used to build,
execute, and start and stop the worker process, as needed. It's
also used to recover the worker process in case that process fails,
to prevent the worker process from being a single point of
failure.
- Exchange Health Manager Worker process
(MSExchangeHMWorker.exe) This is the worker
process responsible for performing the run-time tasks.
Managed availability uses persistent storage to perform its functions:
- XML configuration files are used to initialize the work item
definitions during startup of the worker process.
- The Windows registry is used to store run-time data, such as
bookmarks.
- The Windows crimson channel event log infrastructure is used to
store the work item results.
As illustrated in the following drawing, managed availability includes three main asynchronous components that are constantly doing work.
Managed availability
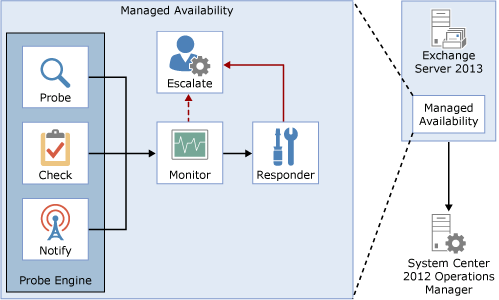
The first component is the probe engine, which is responsible for taking measurements on the server and collecting data. The results of those measurements flow into the second component, the monitor. The monitor contains all of the business logic used by the system based on what is considered healthy on the data collected. Similar to a pattern recognition engine, the monitor looks for the various different patterns on all the collected measurements, and then it decides whether something is considered healthy. Finally, there is the responder engine, which is responsible for recovery actions. When something is unhealthy, the first action is to attempt to recover that component. This could include multi-stage recovery actions; for example, the first attempt may be to restart the application pool, the second may be to restart the service, the third attempt may be to restart the server, and the subsequent attempt may be to take the server offline so that it no longer accepts traffic. If the recovery actions are unsuccessful, the system escalates the issue to a human through event log notifications.
The probe engine contains probes, checks, and notification logic. Probes are synthetic transactions performed by the system to test the end-to-end user experience. Checks are the infrastructure that perform the collection of performance data, including user traffic, and measure the collected data against thresholds that are set to determine spikes in user failures. This enables the checks infrastructure to become aware when users are experiencing issues. Finally, the notification logic enables the system to take action immediately based on a critical event, without having to wait for the results of the data collected by a probe. These are typically exceptions or conditions that can be detected and recognized without a large sample set.
Monitors query the data collected by probes to determine if action needs to be taken based on a predefined rule set. Depending on the rule or the nature of the issue, a monitor can either initiate a responder or escalate the issue to a human via an event log entry. In addition, monitors define how much time after a failure that a responder is executed, as well as the workflow of the recovery action. Monitors have various states. From a system state perspective, monitors have two states:
- Healthy The monitor is operating
properly and all collected metrics are within normal operating
parameters
- Unhealthy The monitor isn't healthy and
has either initiated recovery through a responder or notified an
administrator through escalation.
From an administrative perspective, monitors have additional states that appear in the Shell:
- Degraded When a monitor is in an
unhealthy state from 0 through 60 seconds, it's considered
Degraded. If a monitor is unhealthy for more than 60 seconds, it is
considered Unhealthy.
- Disabled The monitor has been
explicitly disabled by an administrator.
- Unavailable The Microsoft Exchange
Health service periodically queries each monitor for its state. If
it doesn't get a response to the query, the monitor state becomes
Unavailable.
- Repairing An administrator sets the
Repairing state to indicate to the system that corrective action is
in process by a human, which allows the system and humans to
differentiate between other failures that may occur at the same
time corrective action is being taken (such as a database copy
reseed operation).
Get-MailboxDatabaseCopyStatus cmdlet
You can use the Get-MailboxDatabaseCopyStatus cmdlet to view status information about mailbox database copies. This cmdlet enables you to view information about all copies of a particular database, information about a specific copy of a database on a specific server, or information about all database copies on a server. The following table describes possible values for the copy status of a mailbox database copy.
Database copy status
| Database copy status | Description |
|---|---|
|
Failed |
The mailbox database copy is in a Failed state because it isn't suspended, and it isn't able to copy or replay log files. While in a Failed state and not suspended, the system will periodically check whether the problem that caused the copy status to change to Failed has been resolved. After the system has detected that the problem is resolved, and barring no other issues, the copy status will automatically change to Healthy. |
|
Seeding |
The mailbox database copy is being seeded, the content index for the mailbox database copy is being seeded, or both are being seeded. Upon successful completion of seeding, the copy status should change to Initializing. |
|
SeedingSource |
The mailbox database copy is being used as a source for a database copy seeding operation. |
|
Suspended |
The mailbox database copy is in a Suspended state as a result of an administrator manually suspending the database copy by running the Suspend-MailboxDatabaseCopy cmdlet. |
|
Healthy |
The mailbox database copy is successfully copying and replaying log files, or it has successfully copied and replayed all available log files. |
|
ServiceDown |
The Microsoft Exchange Replication service isn't available or running on the server that hosts the mailbox database copy. |
|
Initializing |
The mailbox database copy is in an Initializing state when a database copy has been created, when the Microsoft Exchange Replication service is starting or has just been started, and during transitions from Suspended, ServiceDown, Failed, Seeding, or SinglePageRestore to another state. While in this state, the system is verifying that the database and log stream are in a consistent state. In most cases, the copy status will remain in the Initializing state for about 15 seconds, but in all cases, it should generally not be in this state for longer than 30 seconds. |
|
Resynchronizing |
The mailbox database copy and its log files are being compared with the active copy of the database to check for any divergence between the two copies. The copy status will remain in this state until any divergence is detected and resolved. |
|
Mounted |
The active copy is online and accepting client connections. Only the active copy of the mailbox database copy can have a copy status of Mounted. |
|
Dismounted |
The active copy is offline and not accepting client connections. Only the active copy of the mailbox database copy can have a copy status of Dismounted. |
|
Mounting |
The active copy is coming online and not yet accepting client connections. Only the active copy of the mailbox database copy can have a copy status of Mounting. |
|
Dismounting |
The active copy is going offline and terminating client connections. Only the active copy of the mailbox database copy can have a copy status of Dismounting. |
|
DisconnectedAndHealthy |
The mailbox database copy is no longer connected to the active database copy, and it was in the Healthy state when the loss of connection occurred. This state represents the database copy with respect to connectivity to its source database copy. It may be reported during DAG network failures between the source copy and the target database copy. |
|
DisconnectedAndResynchronizing |
The mailbox database copy is no longer connected to the active database copy, and it was in the Resynchronizing state when the loss of connection occurred. This state represents the database copy with respect to connectivity to its source database copy. It may be reported during DAG network failures between the source copy and the target database copy. |
|
FailedAndSuspended |
The Failed and Suspended states have been set simultaneously by the system because a failure was detected, and because resolution of the failure explicitly requires administrator intervention. An example is if the system detects unrecoverable divergence between the active mailbox database and a database copy. Unlike the Failed state, the system won't periodically check whether the problem has been resolved, and automatically recover. Instead, an administrator must intervene to resolve the underlying cause of the failure before the database copy can be transitioned to a healthy state. |
|
SinglePageRestore |
This state indicates that a single page restore operation is occurring on the mailbox database copy. |
The Get-MailboxDatabaseCopyStatus cmdlet also includes a parameter called ConnectionStatus, which returns details about the in-use replication networks. If you use this parameter, two additional output fields, IncomingLogCopyingNetwork and SeedingNetwork, will be populated in the task's output.
Get-MailboxDatabaseCopyStatus examples
The following examples use the Get-MailboxDatabaseCopyStatus cmdlet. Each example pipes the results to the Format-List cmdlet to display the output in list format.
This example returns status information for all copies of the database DB2.
 Copy Code Copy Code |
|
|---|---|
Get-MailboxDatabaseCopyStatus -Identity DB2 | Format-List |
|
This example returns the status for all database copies on the Mailbox server MBX2.
| Copy Code |
|
|---|---|
Get-MailboxDatabaseCopyStatus -Server MBX2 | Format-List |
|
This example returns the status for all database copies on the local Mailbox server.
| Copy Code |
|
|---|---|
Get-MailboxDatabaseCopyStatus -Local | Format-List |
|
This example returns status, log shipping, and seeding network information for the database DB3 on the Mailbox server MBX1.
| Copy Code |
|
|---|---|
Get-MailboxDatabaseCopyStatus -Identity DB3\MBX1 -ConnectionStatus | Format-List |
|
For more information about using the Get-MailboxDatabaseCopyStatus cmdlet, see Get-MailboxDatabaseCopyStatus.
Test-ReplicationHealth cmdlet
You can use the Test-ReplicationHealth cmdlet to view continuous replication status information about mailbox database copies. This cmdlet can be used to check all aspects of the replication and replay status to provide a complete overview of a specific Mailbox server in a DAG.
The Test-ReplicationHealth cmdlet is designed for the proactive monitoring of continuous replication and the continuous replication pipeline, the availability of Active Manager, and the health and status of the underlying cluster service, quorum, and network components. It can be run locally on or remotely against any Mailbox server in a DAG. The Test-ReplicationHealth cmdlet performs the tests listed in the following table.
Test-ReplicationHealth cmdlet tests
| Test name | Description |
|---|---|
|
ClusterService |
Verifies that the Cluster service is running and reachable on the specified DAG member, or if no DAG member is specified, on the local server. |
|
ReplayService |
Verifies that the Microsoft Exchange Replication service is running and reachable on the specified DAG member, or if no DAG member is specified, on the local server. |
|
ActiveManager |
Verifies that the instance of Active Manager running on the specified DAG member, or if no DAG member is specified, the local server, is in a valid role (primary, secondary, or stand-alone). |
|
TasksRpcListener |
Verifies that the tasks remote procedure call (RPC) server is running and reachable on the specified DAG member, or if no DAG member is specified, on the local server. |
|
TcpListener |
Verifies that the TCP log copy listener is running and reachable on the specified DAG member, or if no DAG member is specified, on the local server. |
|
DagMembersUp |
Verifies that all DAG members are available, running, and reachable. |
|
ClusterNetwork |
Verifies that all cluster-managed networks on the specified DAG member, or if no DAG member is specified, the local server, are available. |
|
QuorumGroup |
Verifies that the default cluster group (quorum group) is in a healthy and online state. |
|
FileShareQuorum |
Verifies that the witness server and witness directory and share configured for the DAG are reachable. |
|
DBCopySuspended |
Checks whether any mailbox database copies are in a state of Suspended on the specified DAG member, or if no DAG member is specified, on the local server. |
|
DBCopyFailed |
Checks whether any mailbox database copies are in a state of Failed on the specified DAG member, or if no DAG member is specified, on the local server. |
|
DBInitializing |
Checks whether any mailbox database copies are in a state of Initializing on the specified DAG member, or if no DAG member is specified, on the local server. |
|
DBDisconnected |
Checks whether any mailbox database copies are in a state of Disconnected on the specified DAG member, or if no DAG member is specified, on the local server. |
|
DBLogCopyKeepingUp |
Verifies that log copying and inspection by the passive copies of databases on the specified DAG member, or if no DAG member is specified, on the local server, are able to keep up with log generation activity on the active copy. |
|
DBLogReplayKeepingUp |
Verifies that replay activity for the passive copies of databases on the specified DAG member, or if no DAG member is specified, on the local server, is able to keep up with log copying and inspection activity. |
Test-ReplicationHealth example
This example uses the Test-ReplicationHealth cmdlet to test the health of replication for the Mailbox server MBX1.
| Copy Code |
|
|---|---|
Test-ReplicationHealth -Identity MBX1 |
|
Crimson channel event logging
Windows includes two categories of event logs: Windows logs, and Applications and Services logs. The Windows logs category includes the event logs available in previous versions of Windows: Application, Security, and System event logs. It also includes two new logs: the Setup log and the ForwardedEvents log. Windows logs are intended to store events from legacy applications and events that apply to the entire system.
Applications and Services logs are a new category of event logs. These logs store events from a single application or component rather than events that might have system-wide impact. This new category of event logs is referred to as an application's crimson channel.
The Applications and Services logs category includes four subtypes: Admin, Operational, Analytic, and Debug logs. Events in Admin logs are of particular interest if you use event log records to troubleshoot problems. Events in the Admin log should provide you with guidance about how to respond to the events. Events in the Operational log are also useful, but may require more interpretation. Admin and Debug logs aren't as user friendly. Analytic logs (which by default are hidden and disabled) store events that trace an issue, and often a high volume of events are logged. Debug logs are used by developers when debugging applications.
Exchange 2013 logs events to crimson channels in the Applications and Services logs area. You can view these channels by performing these steps:
- Open Event Viewer.
- In the console tree, navigate to Applications and Services
Logs > Microsoft > Exchange.
- Under Exchange, select a crimson channel:
HighAvailability or MailboxDatabaseFailureItems.
The HighAvailability channel contains events related to startup and shutdown of the Microsoft Exchange Replication service, and the various components that run within the Microsoft Exchange Replication service, such as Active Manager, the third-party synchronous replication API, the tasks RPC server, TCP listener, and Volume Shadow Copy Service (VSS) writer. The HighAvailability channel is also used by Active Manager to log events related to Active Manager role monitoring and database action events, such as a database mount operation and log truncation, and to record events related to the DAG's underlying cluster.
The MailboxDatabaseFailureItems channel is used to log events associated with any failures that affect a replicated mailbox database.
CollectOverMetrics.ps1 script
Exchange 2013 includes a script called CollectOverMetrics.ps1, which can be found in the Scripts folder. CollectOverMetrics.ps1 reads DAG member event logs to gather information about database operations (such as database mounts, moves, and failovers) over a specific time period. For each operation, the script records the following information:
- Identity of the database
- Time at which the operation began and ended
- Servers on which the database was mounted at the start and
finish of the operation
- Reason for the operation
- Whether the operation was successful, and if the operation
failed, the error details
The script writes this information to .csv files with one operation per row. It writes a separate .csv file for each DAG.
The script supports parameters that allow you to customize the script's behavior and output. For example, the results can be restricted to a specified subset by using the Database or ReportFilter parameters. Only the operations that match these filters will be included in the summary HTML report. The available parameters are listed in the following table.
CollectOverMetrics.ps1 script parameters
| Parameter | Description |
|---|---|
|
DatabaseAvailabilityGroup |
Specifies the name of the DAG from which you want to collect metrics. If this parameter is omitted, the DAG of which the local server is a member will be used. Wildcard characters can be used to collect information from and report on multiple DAGs. |
|
Database |
Provides a list of databases for which the report needs to be
generated. Wildcard characters are supported, for example,
|
|
StartTime |
Specifies the duration of the time period to report on. The script gathers only the events logged during this period. As a result, the script may capture partial operation records (for example, only the end of an operation at the start of the period or vice-versa). If neither StartTime nor EndTime is specified, the script defaults to the past 24 hours. If only one parameter is specified, the period will be 24 hours, either beginning or ending at the specified time. |
|
EndTime |
Specifies the duration of the time period to report on. The script gathers only the events logged during this period. As a result, the script may capture partial operation records (for example, only the end of an operation at the start of the period or vice-versa). If neither StartTime nor EndTime is specified, the script defaults to the past 24 hours If only one parameter is specified, the period will be 24 hours, either beginning or ending at the specified time. |
|
ReportPath |
Specifies the folder used to store the results of event processing. If this parameter is omitted, the Scripts folder will be used. When specified, the script takes a list of .csv files generated by the script and uses them as the source data to generate a summary HTML report. The report is the same one that's generated with the -GenerateHtmlReport option. The files can be generated across multiple DAGs at many different times, or even with overlapping times, and the script will merge all of their data together. |
|
GenerateHtmlReport |
Specifies that the script gather all the information it has recorded, group the data by the operation type, and then generate an HTML file that includes statistics for each of these groups. The report includes the total number of operations in each group, the number of operations that failed, and statistics for the time taken within each group. The report also contains a breakdown of the types of errors that resulted in failed operations. |
|
ShowHtmlReport |
Specifies that the HTML-generated report should be displayed in a Web browser after it's generated. |
|
SummariseCsvFiles |
Specifies that the script read the data from existing .csv files that were previously generated by the script. This data is then used to generate a summary report similar to the report generated by the GenerateHtmlReport parameter. |
|
ActionType |
Specifies the type of operational actions the script should
collect. The values for this parameter are |
|
ActionTrigger |
Specifies which administrative operations should be collected by
the script. The values for this parameter are |
|
RawOutput |
Specifies that the script writes the results that would have been written to .csv files directly to the output stream, as would happen with write-output. This information can then be piped to other commands. |
|
IncludedExtendedEvents |
Specifies that the script collects the events that provide diagnostic details of times spent mounting databases. This can be a time-consuming stage if the Application event log on the servers is large. |
|
MergeCSVFiles |
Specifies that the script takes all the .csv files containing data about each operation and merges them into a single .csv file. |
|
ReportFilter |
Specifies that a filter should be applied to the operations
using the fields as they appear in the .csv files. This parameter
uses the same format as a |
CollectOverMetrics.ps1 examples
The following example collects metrics for all databases that match DB* (which includes a wildcard character) in the DAG DAG1. After the metrics are collected, an HTML report is generated and displayed.
| Copy Code |
|
|---|---|
CollectOverMetrics.ps1 -DatabaseAvailabilityGroup DAG1 -Database:"DB*" -GenerateHTMLReport -ShowHTMLReport |
|
The following examples demonstrate ways that the summary HTML report may be filtered. The first uses the Database parameter, which takes a list of database names. The summary report then contains data only about those databases. The next two examples use the ReportFilter option. The last example filters out all the default databases.
| Copy Code |
|
|---|---|
CollectOverMetrics.ps1 -SummariseCsvFiles (dir *.csv) -Database MailboxDatabase123,MailboxDatabase456
CollectOverMetrics.ps1 -SummariseCsvFiles (dir *.csv) -ReportFilter { $_.DatabaseName -notlike "Mailbox Database*" }
CollectOverMetrics.ps1 -SummariseCsvFiles (dir *.csv) -ReportFilter { ($_.ActiveOnStart -like "ServerXYZ*") -and ($_.ActiveOnEnd -notlike "ServerXYZ*") }
|
|
CollectReplicationMetrics.ps1 script
CollectReplicationMetrics.ps1 is another health metric script included in Exchange 2013. This script provides an active form of monitoring because it collects metrics in real time, while the script is running. CollectReplicationMetrics.ps1 collects data from performance counters related to database replication. The script gathers counter data from multiple Mailbox servers, writes each server's data to a .csv file, and then reports various statistics across all of this data (for example, the amount of time each copy was failed or suspended, the average copy or replay queue length, or the amount of time that copies were outside of their failover criteria).
You can either specify the servers individually, or you can specify entire DAGs. You can either run the script to first collect the data and then generate the report, or you can run it to just gather the data or to only report on data that's already been collected. You can specify the frequency at which data should be sampled and the total duration to gather data.
The data collected from each server is written to a file named CounterData.<ServerName>.<TimeStamp>.csv. The summary report will be written to a file named HaReplPerfReport.<DAGName>.<TimeStamp>.csv, or HaReplPerfReport.<TimeStamp>.csv if you didn't run the script with the DagName parameter.
The script starts Windows PowerShell jobs to collect the data from each server. These jobs run for the full period in which data is being collected. If you specify a large number of servers, this process can use a considerable amount of memory. The final stage of the process, when data is processed into a summary report, can also be quite time consuming for large amounts of data. It's possible to run the collection stage on one computer, and then copy the data elsewhere for processing.
The CollectReplicationMetrics.ps1 script supports parameters that allow you to customize the script's behavior and output. The available parameters are listed in the following table.
CollectReplicationMetrics.ps1 script parameters
| Parameter | Description |
|---|---|
|
DagName |
Specifies the name of the DAG from which you want to collect metrics. If this parameter is omitted, the DAG of which the local server is a member will be used. |
|
DatabaseNames |
Provides a list of databases for which the report needs to be
generated. Wildcard characters are supported for use, for example,
|
|
ReportPath |
Specifies the folder used to store the results of event processing. If this parameter is omitted, the Scripts folder will be used. |
|
Duration |
Specifies the amount of time the collection process should run. Typical values would be one to three hours. Longer durations should be used only with long intervals between each sample or as a series of shorter jobs run by scheduled tasks. |
|
Frequency |
Specifies the frequency at which data metrics are collected. Typical values would be 30 seconds, one minute, or five minutes. Under normal circumstances, intervals that are shorter than these won't show significant changes between each sample. |
|
Servers |
Specifies the identity of the servers from which to collect statistics. You can specify any value, including wildcard characters or GUIDs. |
|
SummariseFiles |
Specifies a list of .csv files to generate a summary report. These files are the files named CounterData.<CounterData>* and are generated by the CollectReplicationMetrics.ps1 script. |
|
Mode |
Specifies the processing stages that the script executes. You can use the following values:
|
|
MoveFilestoArchive |
Specifies that the script should move the files to a compressed folder after processing. |
|
LoadExchangeSnapin |
Specifies that the script should load the Shell commands. This parameter is useful when the script needs to run from outside the Shell, such as in a scheduled task. |
CollectReplicationMetrics.ps1 example
The following example gathers one hour's worth of data from all the servers in the DAG DAG1, sampled at one minute intervals, and then generates a summary report. In addition, the ReportPath parameter is used, which causes the script to place all the files in the current directory.
| Copy Code |
|
|---|---|
CollectReplicationMetrics.ps1 -DagName DAG1 -Duration "01:00:00" -Frequency "00:01:00" -ReportPath |
|
The following example reads the data from all the files matching CounterData* and then generates a summary report.
| Copy Code |
|
|---|---|
CollectReplicationMetrics.ps1 -SummariseFiles (dir CounterData*) -Mode ProcessOnly -ReportPath |
|