

Applies to: Exchange Server 2007 SP3, Exchange Server
2007 SP2, Exchange Server 2007 SP1, Exchange Server 2007
Topic Last Modified: 2007-10-29
In recent years, more businesses have recognized that messaging is fundamental to their success. For many organizations, the messaging system must be part of the business continuity plans, and site resiliency must be designed into their messaging service deployment. Fundamentally, many site resilient solutions involve the deployment of backup hardware in a second datacenter. This often results in the following basic questions:
- What level of service is required after the primary datacenter
fails?
- Do users need their data or just messaging services?
- How rapidly is data required?
- How many users must be supported?
- How will users access their data?
- What is the standby datacenter activation service level
agreement (SLA)?
- How is service moved back to the primary datacenter?
- Are the resources dedicated to the site resilience
solution?
By answering these questions, you begin to shape your site resilience messaging solution. A core requirement of recovery from site failure is to create a solution that gets the necessary messaging data to a backup datacenter that hosts the messaging service.
This topic provides details about several site resilient configurations for the release to manufacturing (RTM) version of Microsoft Exchange Server 2007 and Exchange 2007 Service Pack 1 (SP1). Before you begin to consider site resilience solutions, we recommend that you become familiar with the following terms:
- Stretch cluster Also known as a
geographically dispersed cluster, a cluster configuration where
nodes of the cluster are present in more than one data center.
- Database portability Administrative
task that allows mailboxes to be retargeted at a different server
when their host database is moved.
- Stretched Active Directory
site Active Directory directory
service site that contains computers from more than one datacenter
(for example, an Active Directory site that spans
multiple physical locations).
- Active Directory site membership Member
of a specific Active Directory site based on the
computer's primary IP address. Changing the IP address, or changing
which Active Directory site contains that IP address,
changes the computer's Active Directory site
membership.
- Production datacenter The datacenter
hosting the active servers of a service and it associated
infrastructure.
- Hot backup datacenter A backup
datacenter that is immediately ready to take ownership of the
service and continue its delivery. No special configuration is
required to run the service at this location.
- Warm backup datacenter A backup
datacenter that has servers available to take ownership of the
service for the production datacenter. Activation of the service in
this datacenter requires manual intervention.
- Cold backup datacenter A backup
datacenter that has the capacity and potentially the infrastructure
to take ownership of the service. Significant effort is required
before the service is operational in the datacenter.
- Dedicated Servers that are designated
to only support the users of the primary datacenter.
- Non-Dedicated Servers that are
supporting the users of the primary datacenter, as well as users in
other locations.
Terms such as production, warm, and dedicated can be combined to describe a site resilient deployment. For example, a production data center that is backed up by a dedicated and largely configured backup data center would be called Production:Warm (Dedicated).
 Features that Support Site
Resilience
Features that Support Site
Resilience
There are several Exchange 2007 features that can be used as building blocks for a site resilience solution. They are:
- Stretch clusters, which can be used to replicate data or
simplify activation of the backup datacenter.
- Database portability, which can be used to activate replicated
data.
- Stretched Active Directory sites, which can be used
to support stretched clusters or to enable a backup datacenter.
- Changing a computer's Active Directory site
membership, which can be performed as part of activating a backup
datacenter.
- Regular tape backups in conjunction with offsite storage, which
can be used to recover mailbox data in the backup datacenter.
In addition, third-party products offer data replication, which can be used to transfer data to a backup datacenter. These products can be used in conjunction with stand-alone servers, recovery clusters, or a stretched single copy cluster (SCC). In these configurations, data from the primary server or cluster is replicated to a second server or cluster configuration in a second datacenter. When a site failure occurs, the cluster or server in the second datacenter is manually activated.
In Exchange 2007 SP1, a new feature called standby continuous replication (SCR) has been added, which is specifically designed for site resilience scenarios. As its name implies, SCR is designed for scenarios that use or enable the use of standby recovery servers. SCR extends the existing continuous replication features found in Exchange 2007 RTM and enables new data availability scenarios for Mailbox servers running Exchange 2007 SP1. SCR uses the same log shipping and replay technology used by local continuous replication (LCR) and cluster continuous replication (CCR) to provide added deployment options and configurations.
SCR enables a separation of high availability (comprised of service and data availability) and site resilience. For example, SCR can be combined with CCR to replicate storage groups locally in a primary datacenter (using CCR for high availability) and remotely in a secondary or backup datacenter (using SCR for site resilience). The secondary datacenter could contain a passive node in a failover cluster that hosts the SCR targets. This type of cluster is called a standby cluster because it does not contain any clustered mailbox servers, but it can be quickly provisioned with a replacement clustered mailbox server in a recovery scenario. If the primary datacenter fails or is otherwise lost, the SCR targets hosted in this standby cluster can be quickly activated on the standby cluster.
For more information about SCR, see Standby Continuous Replication.
Solutions to Achieve Site
Resilience
An organization can consider several site resilience solutions. The remainder of this topic provides information about the following site resilience solutions:
- Production:Cold (Dedicated)
- Production:Warm (Dedicated)
- Production:Warm (Non-Dedicated) with two
Active Directory sites
- Production:Production (Non-Dedicated) with one
Active Directory site
The solutions described in this topic assume the complete messaging infrastructure is lost when the production datacenter fails. The backup datacenter must have Internet connectivity and all necessary services to host Exchange. In addition, your activation processes should be scripted and regularly tested.
Production:Cold (Dedicated)
The most basic messaging site resiliency solution is one where the organization has contracts in place for hardware and facilities, but it does not have an active backup datacenter. All mailbox data is regularly backed up and moved off site. Active Directory data is handled in a similar way. Activating the site resilience solution requires that hardware be acquired and deployed. To shorten the overall outage time, the organization can have rapid delivery contracts with hardware vendors for the critical pieces of hardware.
A variation of this solution is to establish the relationship with a disaster recovery vendor who can make the hardware available from a pool that the vendor maintains. This type of relationship may permit the backup data to be maintained at the vendor's location to shorten recovery time. Dedicated storage at the vendor's location can be the replication targets for mailbox and Active Directory data.
For simplicity, it is likely that the deployed configurations will eventually look similar to the production environment or at least some of it. In the midst of a recovery process like this, it is best to work with as much familiar technology and dependencies as possible.
Production:Warm (Dedicated)
In the Production:Warm (Dedicated) recovery model, the production datacenter has a designated backup datacenter with dedicated equipment. The dedicated equipment is used when the production datacenter becomes unavailable. As previously mentioned, the backup datacenter is not automatically activated. The administrator must manually trigger its activation. When triggered, the activation reconfigures the dedicated backup equipment and infrastructure to provide the messaging service. The following figure illustrates a Production:Warm (Dedicated) configuration.
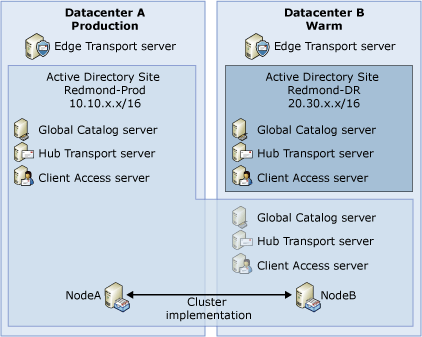
The preceding figure shows the production datacenter (A) hosting Edge Transport, Hub Transport, Client Access, and Mailbox server roles. The warm backup datacenter (B) has dedicated backup servers for each role and for Active Directory. The figure illustrates that simple redundancy is used for all server roles except the Mailbox server role. Mailbox redundancy is handled by a cluster or a standby server configuration with an appropriate replication solution.
The possible mailbox redundancy solutions are:
- Cluster continuous replication (CCR) in a stretch cluster
configuration CCR uses log shipping to create
and manage a second copy of the mailbox data. Thus, the CCR
two-node cluster has a node in each datacenter. In this
configuration, the Windows Cluster service requires subnets that
are stretched between the two locations. The stretch cluster allows
the clustered mailbox server to fail over simply by
registering its assigned IP address again on the node in the other
datacenter.
- Single copy cluster (SCC) with synchronous partner
replication The partner replication allows the
system to have two copies of the Mailbox server data. As with CCR,
a stretched subnet is required for cluster failover to be
successful.
- Standby cluster with partner
replication Mailbox data is replicated to a
second cluster in the backup datacenter, and the server disaster
recovery process is used to restore service. Replication can be
synchronous or asynchronous. No clustering is required, and there
is no stretched subnet requirement.
- Standby server with partner
replication Mailbox data is replicated to a
second server in the backup datacenter, and either database
portability or the server disaster recovery process is used to
restore service. Replication can be synchronous or asynchronous. No
clustering is required, and there is no stretched subnet
requirement.
- Local continuous replication (LCR) with second copy hosted
in second datacenter This isn’t a preferred
solution, but it may be sufficient for some organizations. In this
configuration, Internet SCSI (iSCSI)-based storage is used to store
the passive copy of the data. The network characteristics of the
connection must allow the passive copy to remain reasonably
consistent with the active copy. In this configuration, LCR is
unavailable for rapid local activation because it is unlikely that
network latency and bandwidth will support client access.
The preceding figure illustrates the use of one of the clustered solutions. This is because the Mailbox server is shown in the production datacenter’s Active Directory site. In a clustered solution, the networks on each node in the cluster must be on the same subnet. In a non-clustered solution, a single subnet is not required, but it is recommended. You can use a different subnet if necessary.
Assuming a clustered solution is used, the normal course of operations would be as follows:
- All incoming Internet mail would flow through the Edge
Transport server in Datacenter A.
- All mail destined for Mailbox servers in
Active Directory site Redmond-Prod would be processed by
the Hub Transport servers in Redmond-Prod.
- The clustered mailbox servers in
Active Directory site Redmond-Prod would be hosted on
their configured nodes in Datacenter A or Datacenter B. NodeA and
NodeB are part of Redmond-Prod and are serviced by the Redmond-Prod
Hub Transport and Client Access servers.
- Because CCR supports two nodes, the second node must be in
Datacenter B. This means that an active node failure in Datacenter
A forces the clustered mailbox server to move to Datacenter B; in
this case, it will still be serviced by the Hub Transport servers
and Client Access servers in Datacenter A.
- An SCC with three servers and two copies of the data can be
configured so that a failure causes the clustered mailbox server to
remain in Datacenter A instead of failing over to Datacenter B.
However, if the failure is storage-based, it is still necessary to
activate the passive node in Datacenter B.
The network bandwidth requirements between the two datacenters have three driving factors:
- Cluster service latency
requirements The Cluster service requires no
greater than a half-second round-trip time between the cluster
nodes.
- Bandwidth requirements for
replication CCR requires less bandwidth than
most third-party replication solutions because CCR replication is
based on log shipping and not database copying. The bandwidth
required by a CCR solution depends on a variety of factors that are
typically unique to each environment, and the requirements include
bandwidth for the following:
- Log shipping
- File system notifications, which is how the
Microsoft Exchange Replication service knows when there
is a new log file ready for shipping
- Directory server traffic
- Client traffic, if the clients are not located in the same
physical location as the clustered mailbox server
- Cluster heartbeat traffic
- Cluster database updates
- Any other applications that use the network
- Log shipping
- Hub Transport and Client Access servers require LAN
communication between themselves and the Mailbox servers they
serve For Client Access servers, this
requirement is more important because it serves online users.
Mailbox access to domain controllers can flow over a wide area
network (WAN) connection, and its latency affects online MAPI
access.
The latency and bandwidth requirements may decrease when a non-clustered solution is deployed. The network requirements for replication remain and are significant. However, the majority of the other requirements are not present unless you envision activating the backup Mailbox server without the complete failure of Datacenter A.
When the production datacenter fails, the administrator can restore mail flow and messaging services by doing one of the following:
- Moving the Mailbox servers in the backup datacenter into the
Active Directory site Redmond-DR.
- Moving the Hub Transport, Client Access, and directory servers
in the backup datacenter into the Active Directory site
Redmond-Prod.
The second option is the recommended strategy because it minimizes the impact on other parts of the environment. For example, Exchange servers in any branch offices do not need to change their perceived routing for queued mail. They simply connect when the correct servers are up and available.
The activation of Datacenter B follows these high-level steps:
- The network infrastructure is brought online.
- The Active Directory infrastructure is brought online.
- The remaining Mailbox server is brought online. This step may
involve forcing the cluster to come online with the single
remaining server.
- The Active Directory site Redmond-Prod is updated
with the IP addresses of the Hub Transport, Client Access, and
directory servers in Redmond-DR.
- The MX record for the organization's domains is updated with
the IP address of the Edge Transport server in Datacenter B.
- The newly moved Client Access server is added to a Network Load
Balancing (NLB) configuration.
- Datacenter A messaging service is restored in Datacenter B.
When Datacenter A is available, Datacenter B can be deactivated using these high-level steps:
- Datacenter A individual servers are brought online. They will
participate in providing the service unless Exchange services are
manually stopped or disabled. When migrating back, allow Datacenter
A servers to come online.
- Allow the Hub Transport servers in Datacenter B to drain their
queues, and then take them offline.
- Take Client Access servers in Datacenter B out of the NLB
configuration. Clients then connect through the servers in
Datacenter A.
- The MX record for the organization's domains is updated with
the IP address of the Edge Transport server in Datacenter A.
- Perform any required networking infrastructure updates.
- Move the clustered mailbox servers to Datacenter A.
- Update Active Directory site Redmond-DR with the IP
addresses of the servers that were moved during the activation.
- Datacenter A messaging service is restored.
As with any site failure solution, the activation of the production and backup datacenter should be scripted and tested regularly. Using a clustered solution for the Mailbox server decreases activation times for the backup datacenter. Other solutions may have some Domain Name System (DNS) and Active Directory replication required that can affect when mail flow resumes and clients are able to access their mailbox.
The Production:Warm (Dedicated) solution has the advantage that the dedicated computers provide a predictable level of service.
Production:Warm (Non-Dedicated)
with Two Active Directory Sites
In the Production:Warm (Dedicated) configuration, the Edge Transport, Hub Transport, and Client Access servers in the backup datacenter are dedicated as standby resources for Datacenter A. That configuration represents a significant hardware investment that is not being fully used. An alternative model is represented in the following figure.
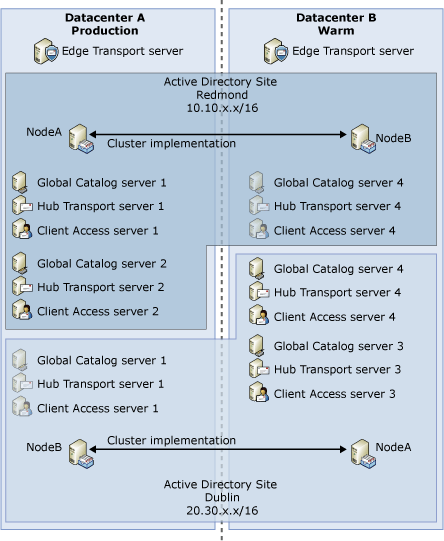
Production:Warm (Non-Dedicated) requires the administrator to manually trigger activation of the backup datacenter. When triggered, the activation process reconfigures some equipment and infrastructure in the backup datacenter to take over messaging service for the users of Datacenter A.
As with the Production:Warm (Dedicated) solution, there are two Active Directory sites in the Production:Warm (Non-Dedicated) solution. But unlike the Production:Warm (Dedicated) solution, both Active Directory sites span to the other datacenter. The dedicated resources in the backup datacenter have become redundant servers for a different production configuration in the backup datacenter. This approach makes these resources available for normal use, thereby creating two production datacenters that are effectively a backup for each other.
For example, as shown in the figure Example Production:Warm (Non-Dedicated) deployment, when Datacenter A fails, Hub Transport server 4, Client Access server 4 and Global Catalog server 4 are added to Active Directory site Redmond, and in conjunction with Redmond NodeB, serve the users of Datacenter A to deliver the messaging service. After the site failure, the two production environments are now running at reduced capacity and reduced redundancy compared with their normal state. Assuming their ongoing load can be supported, this configuration is acceptable. For example, Internet mail is going through the Edge Transport server in Datacenter B. To support an extended datacenter outage, the business can have vendor contracts that rapidly provide additional hardware when requested. The added hardware could then be used to restore redundancy or add additional capacity.
The normal operation of the Redmond and Dublin Active Directory site deployments would be the same for this solution as they are for the Production:Warm (Dedicated) solution. Similarly, the network bandwidth between the two locations would have the same driving factors, except that both Redmond and Dublin servers need to be concurrently supported.
Activation of the backup datacenter is done by either:
- Moving the active node and clustered mailbox server to the
operating datacenter’s Active Directory site.
- Moving Hub Transport, Client Access, and directory servers in
the backup datacenter into the failed datacenter’s
Active Directory site.
The recommended activation solution is to move the Hub Transport and Client Access servers into the failed datacenter’s Active Directory site. This solution results in the simplest and least disruptive activation.
In this solution, the recovery of Datacenter A is accomplished by these high-level steps:
- The network infrastructure is brought online. It is possible
that no network infrastructure changes are required because
Internet mail is already being received by Datacenter B.
- The Active Directory infrastructure for Datacenter A is
brought online (Active Directory site Redmond).
- The remaining Mailbox server is brought online. This step may
involve forcing the cluster to come online with the single
remaining server.
- The Active Directory site Redmond is updated with the
IP addresses of Hub Transport server 4, Client Access server 4, and
Global Catalog server 4.
- Client Access server 3 is added to the NLB configuration for
Redmond.
- Datacenter A messaging service is restored.
When Datacenter A is available, Datacenter B can be restored to its normal configuration using these high-level steps:
- Datacenter A individual servers are brought online. They will
participate in providing the service unless Exchange services are
manually stopped or disabled. When migrating back, allow Datacenter
A servers to come online.
- Allow Hub Transport server 4 to drain its queues, and then take
it offline.
- Take Client Access server 4 out of the NLB configuration.
Clients will still be able to connect to the servers in Datacenter
A.
- Perform any required networking infrastructure updates.
- Move the clustered mailbox server to Datacenter A.
- Update Active Directory site Dublin with the IP addresses
of the servers that were moved during the activation.
- Both datacenters are restored to their original condition.
As with any site failure solution, the activation of the production and backup datacenter should be scripted and tested regularly. Using a clustering solution for the Mailbox server decreases activation times for the backup datacenter. Other mailbox solutions may have some DNS and Active Directory replication required that can affect when mail flow resumes and clients are able to access their mailbox.
This solution allows the servers used for site resilience to be applied to normal operation. This may decrease the cost of the site resilience solution, but it risks not being able to sustain complete system load when required. For example, should the load on the Hub Transport servers in Datacenter B grow to use 80 percent of the capacity, activation of the backup Datacenter for A will exceed Hub Transport capacity. With this solution, administrators must be careful in tracking system utilization over time to make sure that the solution remains viable. Should the load increase, you will need to acquire and deploy new hardware.
Production:Production
(Non-Dedicated) with One Active Directory Site
Organizations that need a solution capable of supporting automatic activation of a backup site must deploy a Production:Production (Non-Dedicated) solution. This solution deploys redundant servers in a single Active Directory site that spans both datacenters, as illustrated in the following figure.
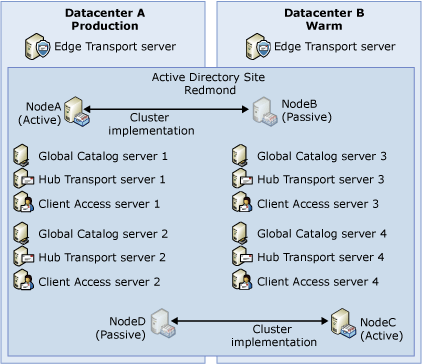
This solution deploys the resources of both datacenters into a single Active Directory site. Any resource in the site may be used to serve most any request. For example, an Edge Transport server in Datacenter A may use a Hub Transport server in Datacenter B to deliver a message to a user whose mailbox is on a clustered mailbox server that is hosted in Datacenter A. Similarly, by default there is no locality of reference for Active Directory traffic. For these reasons, this solution is not recommended.
Activation of the backup datacenter is similar to recovery of multiple server failures. Recovery from activation simply requires restoring service on the failed servers. As with the previously discussed non-dedicated solutions, poor capacity management can result in the load exceeding the service's capacity after a datacenter failure. Administrators must make sure that the solution can support the expected load after a datacenter failure. Failure to do proper capacity management can result in a complete messaging service failure after a single datacenter failure.