

Applies to: Exchange Server 2007 SP3, Exchange Server
2007 SP2, Exchange Server 2007 SP1, Exchange Server 2007
Topic Last Modified: 2009-04-03
Having sufficient capacity is critical. When a database disk runs out of space, the database goes offline. When a transaction log disk runs out of space, it causes all of the databases in that storage group to go offline. Provisioning additional space is often difficult to do quickly, and performing offline compaction to reclaim space can take a long time. In most cases, running out of disk space results in an interruption of availability of one or more databases for a period of time that typically exceeds most recovery time objectives (RTO).
This topic provides information about the following:
- Mailbox storage calculator for Exchange 2007
- Database LUN capacity
- Log LUN capacity
- Transactional I/O
- Predicting Exchange 2007 baseline IOPS
- Non-transactional I/O
- LUNs and physical disks
- Impact of continuous replication on storage design
 Mailbox Storage Calculator for
Exchange 2007
Mailbox Storage Calculator for
Exchange 2007
The Exchange Server 2007 Mailbox Server Role Storage Requirements Calculator (storage calculator) enables you to determine your storage requirements (I/O performance and capacity) and an optimal logical unit number (LUN) layout based on a set of input factors. There are many input factors that need to be accounted for before you can design an optimal storage solution for an Exchange 2007 Mailbox server. These input factors are described throughout this topic.
The storage calculator enables you to input values specific to your organization and provides you with recommendations for the I/O requirements, capacity requirements, and the optimal LUN layout.
For more information about the storage calculator, including details about using it, see Exchange 2007 Mailbox Server Role Storage Requirements Calculator (where you can also download the calculator) on the Exchange Team blog.
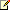 Note: Note: |
|---|
| The content of each blog and its URL are subject to change without notice. The content within each blog is provided "AS IS" with no warranties, and confers no rights. Use of included script samples or code is subject to the terms specified in the Microsoft Terms of Use. |
Database LUN Capacity
There are several data points that you will use to determine how to size a database logical unit number (LUN). In addition, there are other factors to consider. After all factors have been considered and calculated, we recommend that you include an additional overhead factor for the database LUN of 20 percent. This value will account for the other data that resides in the database that is not necessarily seen when calculating mailbox sizes and white space. For example, the data structure (tables, views, and internal indices) within the database adds to the overall size of the database. For example, if after reading the following subsections, you determine that you need 120 gigabytes (GB), we recommend that you provision 144 GB, representing a 20 percent safety overhead for that storage group's database LUN.
Mailbox Quota
The first metric to understand is mailbox size. Knowing the amount of data that an end user is allowed to store in his or her mailbox allows you to determine how many users can be housed on the server. Although final mailbox sizes and quotas change, having a goal is the first step in determining your needed capacity. For example, if you have 5,000 users on a server with a 250 megabyte (MB) mailbox quota, you need at least 1.25 terabytes of disk space. If a hard limit is not set on mailbox quotas, it will be difficult to estimate how much capacity you will need.
Database White Space
The database size on the physical disk is not just the number of users multiplied by the user quota. When the majority of users are not near their mailbox quota, the databases will consume less space, and white space is not a capacity concern. The database itself will always have free pages, or white space, spread throughout. During online maintenance, items marked for removal from the database are removed, which frees these pages. The percentage of white space is constantly changing with the highest percentage immediately after online maintenance and the lowest percentage immediately before online maintenance.
The size of white space in the database can be approximated by the amount of mail sent and received by the users with mailboxes in the database. For example, if you have 100 2-GB mailboxes (total of 200 GB) in a database where users send and receive an average of 10 MB of mail per day, the white space is approximately 1 GB (100 mailboxes × 10 MB per mailbox).
White space can grow beyond this approximation if online maintenance is not able to complete a full pass. It is important that your operational activities include enough time for online maintenance to run each night, so that a full pass can complete within one week or less.
Database Dumpster
Each database has a dumpster that stores soft-deleted items. By default, items are stored for 14 days in Microsoft Exchange Server 2007. These include items that have been removed from the Deleted Items folder. By default, compared with Exchange Server 2003, Exchange 2007 increases the overhead consumed by the database dumpster because deleted items are now stored for twice as long. The actual amount in the dumpster will depend on the size of each item and your organization's specific retention settings.
After the retention period has passed, these items will be removed from the database during an online maintenance cycle. Eventually, a steady state will be reached where your dumpster size will be equivalent to two weeks of incoming/outgoing mail, as a percentage of your database size. The exact percentage depends on the amount of mail deleted and on individual mailbox sizes.
The dumpster adds a percentage of overhead to the database dependent upon the mailbox size and the message delivery rate for that mailbox. For example, with a constant message delivery rate of 52 MB per week, a 250-MB very heavy profile mailbox would store approximately 104 MB in the dumpster, which adds 41 percent overhead. A 1-GB mailbox storing the same 104 MB in the dumpster adds 10 percent overhead.
Actual Mailbox Size
Over time, user mailboxes will reach the mailbox quota, so an amount of mail equivalent to the incoming mail will need to be deleted to remain under the mailbox quota. This means that the dumpster will increase to a maximum size equivalent to two weeks of incoming/outgoing mail. If the majority of users have not reached the mailbox quota, only some of the incoming/outgoing mail will be deleted, so the growth will be split between the dumpster and the increase in mailbox size. For example, a 250-MB very heavy message profile mailbox that receives 52 MB of mail per week (with an average message size of 50 kilobytes (KB)) would result in 104 MB in the dumpster (41 percent), and 7.3 MB in white space, for a total mailbox size of 360 MB. Another example is a 2-GB very heavy message profile mailbox that receives 52 MB of mail per week, which results in 104 MB in the dumpster (5 percent) and 7.3 MB in white space, for a total mailbox size of 2.11 GB. Fifty 2-GB mailboxes in a storage group total 105.6 GB.
The following is a formula for database size using a 2-GB mailbox:
Mailbox Size = Mailbox Quota + White Space + (Weekly Incoming Mail × 2)
Mailbox Size = 2,048 MB + (7.3 MB) + (52 MB × 2)
2,159 MB = 2,048 MB + 7.3 MB + 104 MB (5 percent larger than the quota)
After you have determined the projected actual mailbox size, you can use that value to determine the maximum number of users per database. Take the projected mailbox size, and divide it by the maximum recommended database size. This will also help you determine how many databases you will need to handle the projected user count, assuming fully populated databases. Be aware that due to non-transactional input/output (I/O) or because of hardware limitations, you may have to modify the number of users placed on a single server. Some administrators will prefer to use more databases to further shrink the database size. This approach can assist with backup and restore windows at the cost of more complexity in managing more databases per server.
Content Indexing
Content indexing creates an index, or catalog, that allows users to easily and quickly search through their mail items rather than manually search through the mailbox. Exchange 2007 creates an index that is about 5 percent of the total database size, which is placed on the same LUN as the database. An additional 5 percent capacity needs to be factored into the database LUN size for content indexing.
Maintenance
A database that needs to be repaired or compacted offline will need capacity equal to the size of the target database plus 10 percent. Whether you allocate enough space for a single database, a storage group, or a backup set, additional space will need to be available to perform these operations.
Recovery Storage Group
If you plan to use a recovery storage group as part of your disaster recovery plans, enough capacity will need to be available to handle all of the databases you want to be able to simultaneously restore on that server.
Backup to Disk
Many administrators perform streaming online backups to a disk target. If your backup and restore design involves backup to disk, enough capacity needs to be available on the server to house the backup. Depending on the backup type you use, this capacity can be as small as the database and logs to as large as the database and all logs since the last full backup.
Log LUN Capacity
The transaction log files are a record of every transaction performed by the database engine. All transactions are written to the log first, and then lazily written to the database. Unlike previous versions of Exchange, the transaction log files in Exchange 2007 have been reduced in size from 5 MB to 1 MB. This change was made to support the continuous replication features and to minimize the amount of data loss if primary storage fails.
The following table can be used to estimate the number of transaction logs that will be generated on an Exchange 2007 Mailbox server where the average message size is 50 KB.
Number of generated transaction logs for each mailbox profile
| Mailbox profile | Message profile | Logs generated / mailbox |
|---|---|---|
|
Light |
5 sent/20 received |
6 |
|
Average |
10 sent/40 received |
12 |
|
Heavy |
20 sent/80 received |
24 |
|
Very heavy |
30 sent/120 received |
36 |
|
Extra heavy |
40 sent/160 received |
48 |
The following guidelines have been established for how message size affects log generation rate:
- If the average message size doubles to 100 KB, the logs
generated per mailbox increases by a factor of 1.9. This number
represents the percentage of the database that contains the
attachments and message tables (message bodies and
attachments).
- Thereafter, as message size doubles beyond 100 KB, the log
generation rate per mailbox also doubles.
For example:
- If you have a mailbox profile of Heavy and an average message
size of 100 KB, the logs generated per mailbox is 24 × 1.9 =
46.
- If you have a mailbox profile of Heavy and an average message
size of 200 KB, the logs generated per mailbox is 24 × 3.8 =
91.
Backup and Restore Factors
Most enterprises that perform a nightly full backup will allocate the capacity of about three days of log files in a storage group on the transaction log LUN. This is done to prevent a backup failure from causing the log drive to fill, which would dismount the storage group.
Log LUN sizing is somewhat dependent on your backup and restore design. For example, if your design allows you to go back two weeks and replay all of the logs generated since then, you will need two weeks of log file space. If your backup design includes weekly full and daily differential backups, the log LUN needs to be larger than an entire week of log file space to allow both backup and replay during restore.
Move Mailbox Operations
Moving mailboxes is a primary capacity factor for large mailbox deployments. Many large companies move a percentage of their users on a nightly or weekly basis to different databases, servers, or sites. If your organization does this, you may find it necessary to provide extra capacity to the log LUN to accommodate user migrations. Although the source server will log the record deletions, which are small, the target server must write all transferred data first to transaction logs. If you generate 10 GB of log files in one day, and keep a 3-day buffer of 30 GB, moving 50 2-GB mailboxes (100 GB) would fill your target log LUN and cause downtime. In cases such as these, you may have to allocate additional capacity for the log LUNs to accommodate your move mailbox practices.
Log Growth Factor
For most deployments, we recommend that you add an overhead factor of 20 percent to the log size (after all other factors have been considered) when creating the log LUN to ensure necessary capacity exists in moments of unexpected log generation.
Mailbox Capacity Planning
Example
The following example illustrates appropriate sizing for an environment in which there are 4,000 1-GB very heavy message profile mailboxes on a single clustered mailbox server in a cluster continuous replication (CCR) environment. These mailboxes receive an average of 52 MB of mail per week, with an average message size of 50 KB. The following table provides example values that determine actual mailbox size.
Example values for determining actual mailbox size on disk
| Mailbox size | Dumpster size (2 weeks) | White space | Total size on disk |
|---|---|---|---|
|
1 GB |
104 MB (2 × 52 MB) |
7.3 MB |
1.11 GB (+ 11%) |
In this environment, each user will consume 1.11 GB of disk space. Because the maximum recommended database size in a CCR environment is 200 GB, the server should host no more than 180 mailboxes per database. To support 4,000 mailboxes, it is necessary to have 23 databases, and in this environment, there would also be 23 storage groups. Because a CCR environment requires one database per storage group, each database is in its own storage group. This results in a final mailbox per storage group count of 174. Based on the number of mailboxes and the actual size of the mailboxes, the database size is 193 GB as shown in the following table.
Database capacity requirements
| Mailboxes per database | Total number of databases | Database size requirements |
|---|---|---|
|
174 |
23 |
193 GB |
To ensure that the Mailbox server does not sustain any outages as a result of space allocation issues, the transaction logs also need to be sized to accommodate all of the logs that will be generated during the backup set. Many organizations use a daily full backup strategy plan for three times the daily log generation rate in the event that backup fails. When using a weekly full and then differential or incremental backup, at least one week of log capacity is required to handle the restore case. Knowing that a very heavy message profile mailbox on average generates 42 transaction logs per day, a 4,000-mailbox server will generate 168,000 transaction logs each day. This means that each storage group will generate 7,304 logs. Ten percent of the mailboxes are moved per week on one day (Saturday), and the backup regime includes weekly full and daily incremental backups. In addition, the server can tolerate three days without log truncation. As shown in the following table, this server requires 38.8 GB of space for each storage group.
Log capacity requirements
| Logs per storage group | Log file size | Daily log size | Move mailbox size | Incremental restore size | Log size requirements |
|---|---|---|---|---|---|
|
7,304 |
1 MB |
7.13 GB |
17 GB (17 × 1 GB) |
21.4 GB (3 × 7.13 GB) |
38.8 GB (17.4 + 21.4) |
The transaction log LUN needs to be large enough to handle both the logs generated by the mailbox move operation, and needs to have enough space to restore an entire week of logs.
Transactional I/O
Transactional I/O is the disk I/O caused by users using the server. For example, receiving, sending, and deleting items causes disk I/O. Microsoft Outlook users that are not using Cached Exchange Mode are directly affected by poor disk latency, and this is one of the most important concerns in storage design. For storage, the transactional I/O requirements have been reduced, and with continuous replication, high availability no longer means having to use expensive Fibre Channel storage (although that is still a good solution).
Understanding IOPS
In previous versions of Exchange Server, one of the key metrics needed for sizing storage is the amount of database I/O per second (IOPS) consumed by each user. To measure your user IOPS, take the amount of I/O (both reads and writes) on the database LUN for a storage group, and divide that by the number of users in that storage group. For example, 1,000 users causing 1,000 I/Os on the database LUN means you have an IOPS of 1.0 per user.
Measure Baseline IOPS
If you are using a previous version of Exchange Server and have calculated your baseline IOPS, keep in mind that Exchange 2007 will affect your baseline in the following ways:
- The number of users on the server will affect the overall
database cache per user.
- The amount of RAM influences how large your database cache can
grow, and a larger database cache results in more cache read hits,
thereby reducing your database read I/O.
The key is that knowing your IOPS on a particular server is not enough to plan an entire enterprise because the amount of RAM, number of users, and number of storage groups will likely be different on each server. After you have your actual IOPS numbers, always apply a 20 percent I/O overhead factor to your calculations to add some reserve. You do not want a poor user experience because activity is heavier than normal.
Database Cache
A 64-bit Windows Server operating system running the 64-bit version of Exchange 2007 substantially increases the virtual address space, and allows Exchange to increase its database cache, reduce database read I/O, and enable up to 50 databases per server.
The database read reduction depends on the amount of database cache available to the server and the user message profile. For guidance on memory and storage groups, see Planning Processor Configurations. Following the guidance in that topic can result in up to a 70 percent transactional I/O reduction over Exchange 2003. The amount of database cache per user is a key factor in the actual I/O reduction.
The following table demonstrates the increase in actual database cache per user when comparing the default 900 MB in Exchange 2003 versus 5 MB of database cache per user in Exchange 2007. It is this additional database cache that enables more read hits in cache, thus reducing database reads at the disk level.
Database cache sizes based on mailbox count
| Mailbox count | Exchange 2003 database cache/mailbox (MB) | Exchange 2007 database cache/mailbox (MB) | Database cache increase over Exchange 2003 |
|---|---|---|---|
|
4,000 |
0.225 |
5 |
23 times |
|
2,000 |
0.45 |
5 |
11 times |
|
1,000 |
0.9 |
5 |
6 times |
|
500 |
1.8 |
5 |
3 times |
Predicting Exchange 2007
Baseline IOPS
The two largest factors that can be used to predict Exchange 2007 database IOPS are the amount of database cache per user and the number of messages each user sends and receives per day. The following formula is based on a standard worker who uses Office Outlook 2007 in Cached Exchange Mode, and it has been tested to be accurate within plus or minus 20 percent. Other client types and usage scenarios may yield inaccurate results. The predictions are only valid for user database cache sizes between 2 MB and 5 MB. The formula has not been validated with users sending and receiving over 150 messages per day. The average message size for formula validation was 50 KB, but message size is not a primary factor for IOPS.
The following table provides estimated values for IOPS per user that you can use to predict your baseline Exchange 2007 IOPS requirements.
Database cache and estimated IOPS per user based on user profile and message activity
| User type (usage profile) | Send/receive per day approximately 50-KB message size | Database cache per user | Estimated IOPS per user |
|---|---|---|---|
|
Light |
5 sent/20 received |
2 MB |
0.11 |
|
Average |
10 sent/40 received |
3.5 MB |
0.18 |
|
Heavy |
20 sent/80 received |
5 MB |
0.32 |
|
Very heavy |
30 sent/120 received |
5 MB |
0.48 |
|
Extra heavy |
40 sent/160 received |
5 MB |
0.64 |
To estimate database cache size, subtract 2,048 MB, or 3,072 MB when using local continuous replication (LCR), from the total amount of memory installed in the Exchange server, and divide that amount by the number of users. For example, for a server with 3,000 users and 16 GB of RAM, deduct 2 GB for the system, leaving 14 GB of RAM, or 4.66 MB per user (14 GB ÷ 3,000 = 4.66 MB).
Knowing that the average per-user database cache size is 4.66 MB and that the average number of messages sent and received per day is 60, you can estimate both database reads and writes:
- Database reads Multiply the 60 messages
per day by 0.0048, which results in 0.288. Next, take the amount of
database cache per mailbox (4.66 MB) to the -0.65th power (5 ^
-0.65), which results in 0.3622. Finally, multiply the two figures,
which results in 0.104 database reads per user (0.288 × 0.3622 =
0.104).
- Database writes Multiply the number of
messages per user (60) by 0.00152, which results in 0.0912 database
writes per user.
The formula to use is:
((0.0048 × M) × (D ^ -0.65)) + (0.00152 × M) = total database IOPS
where M is the number of messages and D is the database cache, per user. The total database IOPS per user is the addition of both reads and writes, which in this example is 0.189 IOPS:
((0.0048 × 60) × (4.66 ^ -0.65)) + (0.00152 × 60) = 0.189
The following graph demonstrates the databases read and write reduction achieved when running Exchange 2007 with 4,000 - 250 MB mailboxes simulating Outlook 2007 in Cached Exchange Mode and the recommended server memory.
Effect of Online Mode Clients
Unlike Cached Exchange Mode clients, all Online Mode client operations occur against the database. As a result, read I/O operations will increase against the database. Therefore, the following guidelines have been established if the majority of clients will operate in Online Mode:
- 250 MB Online Mode clients will increase database read
operations by a factor of 1.5 when compared with Cached Exchange
Mode clients. Below 250 MB, the impact is negligible.
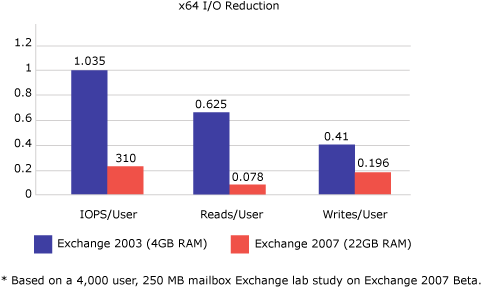
- As mailbox size doubles, the database read IOPS will also
double (assuming equal item distribution between key folders
remains the same).
The following graph illustrates IOPS based on mailbox size.
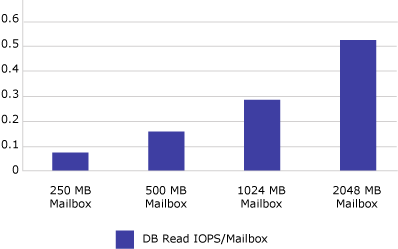
Testing has also shown that increasing the database cache beyond 5 MB per mailbox will not significantly reduce the database read I/O requirements. The following graph depicts 2-GB mailboxes using Online Mode clients and the effect increasing the cache beyond 5 MB has on reducing the database read I/O requirements.
As a result of this data, two recommendations can be made:
- Deploy cached mode clients where appropriate. See the "Item
Count per Folder" section below for more information.
- Ensure that the I/O requirements are taken into consideration
when designing the database storage.
For additional IOPS factors, such as third-party clients, see Optimizing Storage for Exchange Server 2003.
Database Read/Write Ratios
In Exchange 2003, the database read/write ratio is typically 2:1 or 66 percent reads. With Exchange 2007, the larger database cache decreases the number of reads to the database on disk causing the reads to shrink as a percentage of total I/O. If you follow the recommended memory guidelines and use Cached Exchange Mode, the read/write ratio should be closer to 1:1, or 50 percent reads.
When using Outlook in Online Mode, or when using desktop search engines, the read/write ratio will increase slightly on the read side (depending on the mailbox size). Having more writes as a percentage of total I/O has particular implications when choosing a redundant array of independent disks (RAID) type that has significant costs associated with writes, such as RAID5 or RAID6. For more information about selecting the appropriate RAID solution for your servers, see Storage Technology.
Log to Database Ratio
In Exchange 2003, a transaction log for a storage group requires approximately 10 percent as many I/Os as the databases in the storage group. For example, if the database LUN is using 1,000 I/Os, the log LUN would use approximately 100 I/Os. With the reduction in database reads in Exchange 2007, combined with the smaller log file size and the ability to have more storage groups, the log-to-database write ratio is approximately 3:4. For example, if the database LUN is consuming 500 write I/Os, the log LUN will consume approximately 375 write I/Os.
After measuring or predicting the transactional log I/O, apply a 20 percent I/O overhead factor to ensure adequate room for busier than normal periods. Also, when using continuous replication, closed transaction logs must be read and sent to a second location. This overhead is an additional 10 percent in log reads. If the transaction log for a storage group is consuming 375 write I/Os, you can expect an additional 37.5 read I/Os when using continuous replication.
Item Count per Folder
Understanding the Performance Impact of High Item Counts and Restricted Views explains how the number of items in your critical folders and the type and mode of client being used can affect disk performance for some users.
One way to reduce server I/O is to use Outlook 2007 in Cached Exchange Mode. The initial mailbox synchronization is an expensive operation, but over time, as the mailbox size grows, the disk subsystem burden is shifted from the Exchange server to the Outlook client. This means that having a large number of items in a user's Inbox, or a user searching a mailbox will have little effect on the server. This also means that Cached Exchange Mode users with large mailboxes may need faster computers than those with small mailboxes (depending on the individual user threshold for acceptable performance). When you deploy client computers that are running Outlook 2007 in Cached Exchange Mode, consider the following with respect to mailbox /.OST sizes:
- Up to 5 gigabytes (GB): This size should provide a good user
experience on most hardware.
- Between 5 GB and 10 GB: This size is typically hardware
dependent. Therefore, if you have a fast hard disk and much RAM,
your experience will be better. However, slower hard drives, such
as drives that are typically found on portable computers or early
generation solid state drives (SSDs), experience some application
pauses when the drives respond.
- More than 10 GB: This is the size at which short pauses begin
to occur on most hardware.
- Very large, such as 25 GB or larger: This size increases the
frequency of the short pauses, especially while you are downloading
new e-mail. Alternatively, you can use Send/Receive groups to
manually sync your mail.
| Note: |
|---|
| This guidance is based on the installation of a cumulative update for Outlook 2007 Service Pack 1 or later, as described in Microsoft Knowledge Base Article 961752, Description of the Outlook 2007 hotfix package (Outlook.msp): February 24, 2009,. |
If you experience performance-related issues with your Outlook 2007 in Cached Exchange Mode deployment, see Knowledge Base Article 940226, How to troubleshoot performance issues in Outlook 2007.
Both Outlook Web Access and Outlook in Online Mode store indexes on and search against the server's copy of the data. For moderately sized mailboxes, this results in approximately double the IOPS per mailbox of a comparably sized Cached Exchange Mode client. The IOPS per mailbox for large mailboxes is even higher. The first time you sort a view in a new way, an index is created, causing many read I/Os to the database LUN. Subsequent sorts on an active index are inexpensive.
A challenging scenario is when a user has gone beyond the number of indexes that Exchange will store, which for Exchange 2007 is 11 indexes. When the user chooses to sort a new way, thereby creating a twelfth index, it causes additional disk I/O. Because the index is not stored, this disk I/O cost occurs every time that sort is done. Because of the high I/O that can be generated in this scenario, we strongly recommend storing no more than 20,000 items in core folders, such as the Inbox and Sent Items folders. Creating more top-level folders, or subfolders underneath the Inbox and Sent Items folders, greatly reduces the costs associated with this index creation, so long as the number of items in any one folder does not exceed 20,000. For more information about how item counts affect Mailbox server performance, see Recommended Mailbox Size Limits and Understanding the Performance Impact of High Item Counts and Restricted Views.
| Note: |
|---|
| The content of each blog and its URL are subject to change without notice. The content within each blog is provided "AS IS" with no warranties, and confers no rights. Use of included script samples or code is subject to the terms specified in the Microsoft Terms of Use. |
For more information about the improvements that are available, see Knowledge Base article 968009, Outlook 2007 improvements in the February 2009 cumulative update.
Non-Transactional I/O
Transactional I/O occurs in response to direct user action and usually has the highest priority, and it is the focus for storage design. The reduction in transactional I/O makes non-transactional I/O more important. With large mailboxes, particularly in the case of a 2-GB mailbox, many enterprises are not doubling the user capacity, but in some cases increasing it tenfold. One such example would be moving from 200 MB to 2 GB. When you have such a significant increase in the amount of data on disk, you must now consider and account for non-transactional I/O when planning your storage design.
Content Indexing
In Exchange 2007, messages are indexed as they are received, causing little disk I/O overhead. Searching against the index in Exchange 2007 is approximately 30 times faster than in Exchange 2003.
Messaging Records Management
Messaging records management (MRM) is a new feature in Exchange 2007 that helps administrators and users manage their mailboxes. Policies can be set to move or delete mail that meets specific thresholds, such as age. MRM is a scheduled crawl that runs against the database in a synchronous read operation similar to backup and online maintenance. The disk cost of MRM depends upon the number of items requiring action (for example, delete or move).
We recommend that MRM not run at the same time as either backup or online maintenance. If you use continuous replication, you can offload Volume Shadow Copy Service (VSS) backups to the passive copy, allowing more time for online maintenance and MRM so that they do not affect one another or users.
Online Maintenance
Many actions are performed when the database runs online maintenance, such as permanently removing deleted items and performing online defragmentation of the database. Maintenance causes reads, while online defragmentation causes both reads and writes. The amount of time it takes to complete maintenance is proportional to the size of the database and can be a limiting factor on how large databases are allowed to grow. For more information about online maintenance, see Store Background Processes Part I.
| Note: |
|---|
| The content of each blog and its URL are subject to change without notice. The content within each blog is provided "AS IS" with no warranties, and confers no rights. Use of included script samples or code is subject to the terms specified in the Microsoft Terms of Use. |
Backup and Restore
Many different backup and restore methods are available to the administrator. The key metric with backup and restore is the throughput, or the number of megabytes per second that can be copied to and from your production LUNs. After you determine the throughput, you need to decide if it is sufficient to meet your backup and restore service level agreement (SLA). For example, if you need to be able to complete the backup within four hours, you may have to add more hardware to achieve it. Depending on your hardware configuration, there may be gains that can be achieved by changing the allocation unit size. This can help with both streaming online backups, and the Exchange Server Database Utilities (Eseutil.exe) integrity check that occurs during a VSS backup.
With 2,000 users on a server, moving from a 200-MB mailbox to a 2-GB mailbox increases the database size tenfold. Many administrators are not accustomed to having to deal with large amounts of data on a single server. Consider a server with 2,000 2-GB mailboxes. With the overhead described previously, this is more than 4 terabytes of data. Assuming you can achieve a backup rate of 175 GB per hour (48 MB per minute), it would take at least 23 hours to back up the server. An alternative for servers that do not use LCR or CCR might be to perform a full backup of one-seventh of the databases each day, and an incremental backup on the remainder, as illustrated in the following table.
Example of a weekly backup routine
| Backup type | Day 1 | Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Day 7 |
|---|---|---|---|---|---|---|---|
|
Full |
DB 1–2 |
DB 3–4 |
DB 5–6 |
DB 7–8 |
DB 9–10 |
DB 11–12 |
DB 13–14 |
|
Incremental |
DB 3–14 |
DB 1–2 DB 5–14 |
DB 1–4 DB 7–14 |
DB 1–6 DB 9–14 |
DB 1–8 DB 11–14 |
DB 1–10 DB 13–14 |
DB 1–12 |
As you can see from the preceding table, the total amount of data backed up nightly is approximately 650 GB, which could complete in 3.7 hours, assuming a rate of 175 GB per hour. Some solutions can achieve more or less throughput. However, large mailboxes may require different approaches.
With LCR and CCR, the passive copy is the first line of defense. You only restore from backup if both the active copy and the passive copy fail or are otherwise unavailable. Recovering multiple days of incremental logs can add to the length of time it takes to recover. For this reason, incremental backup is seldom used on a fast recovery solution, such as CCR or VSS clones. With a VSS clone, the recovery of the data is fast, and adding a little time to replay logs may be acceptable to keep backup times within the backup SLA.
Streaming Online Backup
With streaming backups, we recommend that you separate streaming I/O (source and target) so that multiple storage groups being backed up concurrently do not compete for the same disk resources. Whether the target is disk or tape, there will be a throughput limit on the physical disks and controllers unique to each hardware solution. It may be necessary to isolate some storage groups from each other to maximize the number of concurrent backup operations, and throughput to minimize the size of the backup window. The following table illustrates an example of two concurrent backups of 14 databases.
Example of a concurrent backup routine
| Backup number | LUN 1 | LUN 2 | LUN 3 | LUN 4 | LUN 5 | LUN 6 | LUN 7 |
|---|---|---|---|---|---|---|---|
|
First backup |
storage group (SG) 1 |
SG 2 |
SG 3 |
SG 4 |
SG 5 |
SG 6 |
SG 7 |
|
Second backup |
SG 8 |
SG 9 |
SG 10 |
SG 11 |
SG 12 |
SG 13 |
SG 14 |
You can run streaming backups concurrently, one from each LUN, if you isolate your storage group LUNs from each other, as illustrated in the preceding table. The backup jobs should complete on the first storage group on each LUN before the second storage group begins to back up, isolating the backup streams. Two streaming backup jobs on the same physical disks may not be twice as fast, but it should be faster than a single streaming backup job in terms of megabytes per second.
VSS Backup
Exchange 2007 uses VSS, which is included in Windows Server 2003, to make volume shadow copies of databases and transaction log files. For more information about VSS, including both clone and snapshot techniques, see Best Practices for Using Volume Shadow Copy Service with Exchange Server 2003. New in Exchange 2007 is the ability to make VSS backups of the passive copy of storage groups running in an LCR or CCR environment. In these environments, taking a VSS snapshot from the passive copy removes the disk load on the active LUNs during both the checksum integrity phase of the backup, and the subsequent copy to tape or disk. It also frees up more time on the active LUNs to run online maintenance, MRM, and other tasks.
LUNs and Physical Disks
In many cases, the physical disk, or LUN, that the operating system recognizes is abstracted from the hardware used to present the disk to the operating system. For performance and recovery reasons, it has always been critical to separate transaction log files from the database files at both the LUN and physical disk levels. Mixing random and sequential disk I/O on the same physical disk significantly reduces performance, and from a recovery perspective, separating a storage group's log files and database files makes sure that a catastrophic failure of one set of physical disks does not cause the loss of both database files and log files.
In Exchange 2007, it is a best practice to place all databases in a storage group on the same physical LUN. It is also a best practice to place no more than one database in each storage group. Exchange database I/O is random, and most storage subsystems benefit when the physical disks are performing the same workload. Many storage arrays are designed so that many physical disks are first pooled into a group of disks, and then LUNs are created out of the available space in that disk group and distributed equally across every physical disk. It is acceptable for the physical disks that are backing up a storage group's database LUN to also back up other LUNs that house databases for other storage groups and servers. Likewise, it is not critical to isolate each storage group's transaction log LUN onto separate physical spindles, even though the loss of sequential I/O will slightly impact performance.
In the case where the maximum of 50 storage groups is configured on a single server, each storage group should be given its own transaction log LUN and database LUN. This exceeds the number of available drive letters, and the NTFS file system volume mount points must be used. Fifty storage groups configured for continuous replication require 200 LUNs, which could exceed some storage array maximums, particularly in the case of LCR, where all 200 LUNs must be presented to a single server. As the number of LUNs increases, monitoring becomes even more important because running out of disk space will cause that storage group to dismount.
LUN Design
In many cases, the LUN that the operating system recognizes is abstracted from the physical hardware that is actually behind that disk. It has always been critical to separate transaction logs from the database at both the LUN and physical disk level for performance and recoverability purposes. On some storage arrays, mixing random and sequential I/O on the same physical disks can reduce performance. From the perspective of recovery, separating a storage group's transaction logs and databases makes sure that a catastrophic failure of a particular set of physical disks does not cause a loss of both database and transaction logs.
Exchange database I/O is random, and most storage subsystems benefit when the physical disks are performing the same workload. Many storage arrays use virtual storage so that many physical disks are first pooled into a group of disks, and then LUNs are created from the available space in that disk group and distributed equally across every physical disk. When not using continuous replication, it is acceptable for the physical disks that are backing up a storage group's database LUN to also back up other LUNs that house the databases for other storage groups and servers. Likewise, it is not critical to isolate each storage group's transaction log LUN onto separate physical spindles, even though the loss of sequential I/O will slightly affect performance. It is important to separate the log and database LUNs from the same storage group onto separate physical disks. It is not realistic to dedicate two or four 500-GB physical disks to a single storage group's transaction log LUN when you require 30 IOPS and 5 percent of the capacity.
Although there are many ways to design LUNs in Exchange 2007, we recommend the following two designs to limit complexity:
- Two LUNs per storage group
- Two LUNs per backup set
Two LUNs per Storage Group
Creating two LUNs (one for logs and one for databases) for a storage group was the standard best practice for Exchange 2003. With Exchange 2007, and in the maximum case of 50 storage groups, the number of LUNs you provision depends upon your backup strategy. If your RTO is small, or if you use VSS clones for fast recovery, it may be best to place each storage group on its own transaction log LUN and database LUN. Because this approach will exceed the number of available drive letters, volume mount points must be used.
Some of the benefits of this strategy include:
- Enables hardware-based VSS at a storage group level, providing
single storage group backup and restore.
- Flexibility to isolate the performance between storage
groups.
- Increased reliability. A capacity, corruption, or virus problem
on a single LUN will only affect one storage group.
Some of the concerns with this strategy include:
- Fifty storage groups using continuous replication could require
200 LUNs, which would exceed some storage array maximums,
particularly in the case of LCR, where all 200 LUNs would need to
be presented to a single server.
- A separate LUN for each storage group causes more LUNs per
server, increasing the administrative costs.
Two LUNs per Backup Set
A backup set is the number of databases that are fully backed up in a night. A solution that performs a full backup on one-seventh of the databases nightly could reduce complexity by placing all of the storage groups to be backed up on the same log and database LUN. This can reduce the number of LUNs on the server.
Some of the benefits of this strategy include:
- Simplified storage administration because there are fewer LUNs
to manage.
- Potential reduction of the number of backup jobs.
Some of the concerns with this strategy include:
- Limiting the ability to take hardware-based VSS backups and
restores.
- Limiting how far this strategy would scale in capacity, due to
the 2-terabyte limit on a master boot record (MBR) partition.
Volume Mount Points
There are many cases, such as in multiple node single copy clusters (SCCs), where more LUNs are needed than there are available drive letters. In those cases, you must use volume mount points. Drive letters are a legacy MS-DOS operating system feature to recognize partitions or disks, and it is best to avoid using too many drive letters. It is much easier to place all transaction log and database LUNs on a volume mount point for ease of administration. If you have 20 storage groups, each with a database, it is difficult to remember which drive letter houses database 17. The following table illustrates an example of using volume mount points.
Example folder layout using volume mount points
| Transaction logs (L:) | Databases (P:) |
|---|---|
|
L:\SG1LOG |
P:\SG1DB |
|
L:\SG2LOG |
P:\SG2DB |
|
L:\SG3LOG |
P:\SG3DB |
|
L:\SG4LOG |
P:\SG4DB |
In this example L: and P: are anchor LUNs, which house all the log and database LUNs respectively. Each folder on these drives is a volume mount point to a separate LUN.
Hardware-Based VSS
When using hardware-based VSS, there are a few recommendations for placing Exchange data on the LUNs. For a hardware-based VSS solution, each transaction log LUN and database LUN should only house the files from the chosen backup set. If you want to restore a storage group without affecting any other storage group, you will need a separate transaction log LUN and database LUN for each storage group. If you are willing to take other databases and storage groups offline to restore a single database, you can place multiple storage groups on a single transaction log LUN and database LUN.
Software-Based VSS
When using software-based VSS, particularly with large mailboxes and continuous replication, your backup is a two-step strategy. First, you take a VSS snapshot, and then you stream the flat files to disk or tape.
LUN Reliability
It is always important to place a storage group's transaction logs and databases on separate physical disks because doing so increases reliability. With continuous replication, it is also important to separate the active and passive LUNs on completely separate storage. With CCR and LCR, you want storage resiliency in the event of a catastrophic failure of the primary storage.
LUN Example
Consider the following scenario, which builds upon the previous capacity example, and applies that information to the creation of a LUN. In this example, the backup regime is a daily, full backup. You want to enable content indexing, and you will place it on the database LUN. Five percent of 193 GB is approximately 10 GB. You need to add this to the final LUN size. The growth factor for 193 GB should be 20 percent of the final database size. Twenty percent of 193 GB is 39 GB. Results are shown in the following tables.
Example values for determining database LUN size
| Database size | Growth factor | Content indexing | Database LUN size |
|---|---|---|---|
|
193 GB |
39 GB |
10 GB |
241 GB |
Each storage group creates 7.13 GB of logs per day, and you want to store at least three days of logs.
Example values for determining log LUN size
| Logs (1 day) | Logs (3 days) |
|---|---|
|
7.13 GB |
21.4 GB |
Move Mailbox
Our example organization moves 10 percent of its mailboxes per week, and they perform all moves on Saturday. Thus, the log LUN must handle the entire load one day. A move mailbox strategy used at Microsoft is to distribute the incoming users equally across each of the storage groups. This means that the example server with 4,000 users will move approximately 400 users each Saturday. With 23 storage groups, each storage group must receive seventeen 1-GB mailboxes, as shown in the following table.
Example values for determining move mailbox log LUN size
| Logs (3 days) | Mailbox moves | Log LUN size |
|---|---|---|
|
21.4 GB |
17.64 GB (17 1-GB users) |
46.6 GB (38.8 GB + 20%) |
With this layout, you would never move more than 17 users to a storage group on a single day. Therefore, it may make more sense to increase the size of the log LUN in case you need to move more than 10 percent on any particular day.
Impact of Continuous Replication
on Storage Design
Continuous replication is a new feature in Exchange 2007 where a storage group's database and log files are copied to a secondary location. As new transaction logs are closed, or filled, they are copied to a secondary location, validated, and then replayed into a passive copy of the database. To achieve storage resiliency, we recommend that the passive copy be placed on a completely isolated storage array from the live production LUNs. Because you are depending on the passive copy to handle the production load in the event of a failure, its storage should match the performance and capacity of the storage solution used by the active copy of the storage group.
Each storage group can only contain a single database when using continuous replication, so each copy of the database will require four LUNs. Each database copy will be in its own storage group, which will need a separate log and database LUN for the active copy and a separate log and database LUN for the passive copy.
It is a best practice to:
- Separate the storage into individual LUNs at the hardware
level, and to not create multiple logical partitions of a LUN
within the operating system.
- Separate the transaction logs and databases and house them on
separate physical disks to increase fault tolerance.
- Separate the active and passive LUNs on entirely different
storage arrays so that the storage is not a single point of
failure.
- If hosting storage groups or databases from multiple clustered
mailbox servers on the same storage array, you should ensure that
each LUN is built using separate physical disks.
Your storage design should also maximize fault tolerance by separating the storage controllers on a different Peripheral Component Interconnect (PCI) bus. In addition, you should design storage for the passive copy to match the storage used by the active copy in terms of both capacity and performance. The passive copy's storage is the first line of defense in the event of a catastrophic failure of the active copy's storage, and upon failover, the passive copy will become the active copy. Placing the passive copy's LUNs on completely different storage hardware makes sure that any actions performed against the passive copy do not affect the active copy.
With continuous replication, more transactional I/O is occurring. This factor must be taken into consideration when sizing your server. The active transaction log, which is a sequential write, must also read the log after it has closed and copy it to the replica transaction log LUNs quarantine folder. The log must then be inspected at the replica location and then moved to its final destination on the replica LUN. Finally, the log is read and played into the database. Both active and replica transaction log LUNs must read and write versus the nearly 100 percent sequential write activity found on a stand-alone Mailbox server. This change in behavior may require an evaluation in cache settings on your storage controller. Recommended settings are 25 percent read and 75 percent write on a battery-backed storage controller.
Continuous Replication and Database Size
A larger maximum database size is possible when continuous replication is used. We recommend the following maximum database sizes for Exchange 2007:
- Databases hosted on a Mailbox server without continuous
replication: 100 GB
- Databases hosted on a Mailbox server with continuous
replication and gigabit Ethernet: 200 GB
Note:Large databases may also require newer storage technology for increased bandwidth to accommodate repair scenarios.  Important:
Important:The true maximum size for your databases should be dictated by the SLA in place at your organization. Determining the largest size database that can be backed up and restored within the period specified in your organization's SLA is how you determine the maximum size for your databases.
LCR Storage Options
LCR enables log shipping on a single server. In the event of a catastrophic failure of the storage housing the active copy of the database or log files, the administrator can manually activate the passive copy of the database. The storage for the passive copy should be completely separate from the storage for the active copy. In addition:
- Controller cards should be on a different PCI bus.
- Each storage solution should have its own uninterruptible power
supply (UPS).
- Each storage solution should be on a separate power
circuit.
CCR Storage Options
CCR enables log shipping to a passive node in an active/passive failover cluster. By shipping the logs to and maintaining the passive copy on a completely different server, the operational impact to the active node is decreased, and you have fault tolerance on the server.
In a geographically dispersed CCR deployment, the passive copy can be on a node that is in a different physical location from the active node, thereby providing site resiliency. Although the information in the article Deployment Guidelines for Exchange Server Multi-Site Data Replication still applies, the pull-based technology behind continuous replication means that high latency will not affect the user experience. This is a sharp contrast to the geographically dispersed cluster solution in which synchronous replication latency negatively affects the active server. With CCR, the replication process may run behind, increasing the amount of time that the active copy and passive copy are not synchronized. However, if a disaster affects the active copy, any messages that were not replicated to the passive node will be recoverable because of the transport dumpster feature of the Hub Transport server.
Single Copy Cluster Storage Options
The hardware used for an SCC must be listed in the Cluster category of the Windows Server Catalog. The hardware used for a geographically dispersed SCC must be listed in the Geographically Dispersed Cluster category in the Windows Server Catalog to be supported.
A clustered mailbox server using shared storage has the same fundamental storage considerations as a stand-alone server. When using synchronous replication, disk latency can be artificially increased by the replication process. Care must be used to maximize the points of replication within the storage array. For more information about replication for SCCs, see Deployment Guidelines for Exchange Server Multi-Site Data Replication.