

Applies to: Exchange Server 2007 SP3, Exchange Server
2007 SP2, Exchange Server 2007 SP1, Exchange Server 2007
Topic Last Modified: 2008-01-17
One of the primary development themes for high availability in Microsoft Exchange Server 2007 was to challenge the high availability practices and configuration options that were present in previous versions of Exchange Server. By following a structured planning process with Exchange 2007, you may be able to lower your deployment and operational costs, while at the same time providing more services to your end users.
The high availability solutions in Exchange Server 2003 have been successfully deployed in production by Microsoft and many customers to deliver a highly available messaging environment. In addition, many customers have successfully deployed partner replication technology and have created solutions that automatically fail over to a second copy of the data when a failure occurs. Exchange 2007 includes enhancements to the high availability solutions found in Exchange 2003, and new high availability features that eliminate the need for third-party replication technologies and reduce the costs and complexity of the overall solution. Some of the key reasons behind these improvements were the direct result of feedback from customers who reported that:
- The requirement of shared storage for the solution increased
costs and complexity of the solution. For example, the hardware for
the entire solution had to be selected from the Cluster Solution
category of the Windows Server Catalog of Tested Products. In
Exchange 2007, single copy clusters (SCCs) maintain this
requirement, but clustered mailbox servers that are configured in a
cluster continuous replication (CCR) environment do not have this
requirement.
- The use of a single copy of the mailbox data meant that
failures of that copy or its storage were very disruptive, often
resulting in lengthy outages and sometimes data loss.
- A lack of installation and management integration between the
Cluster service and Exchange Server forced the Exchange
administrator to understand cluster concepts and functionality.
This represented a significant learning curve for some Exchange
administrators.
- The out-of-the-box default configuration settings were not
tuned for optimal recovery behaviors. Administrators were required
to manually reconfigure the default cluster resources and cluster
settings to adhere to best practice recommendations.
- All Exchange services (client access, transport, and storage)
were handled using the same availability strategy even though
architecturally there were some drastic differences among them,
including dissimilar high availability strategies.
- Partner technology was required by some customers to achieve a
solution that maintained two copies of their mailbox data. These
solutions added to the costs and complexity of the deployment.
The high availability solutions in Exchange 2007 are designed to address all of the deficiencies in the Exchange 2003 high availability approach. Exchange 2007 addresses the deficiencies through architectural changes, the support of new configurations, a change in management models, and by introducing new approaches to high availability. The result is a flexible solution that provides each organization with the freedom to choose a solution that meets its specific needs.
 High Availability Deployment
Options
High Availability Deployment
Options
High availability should always be designed both at the individual component level and in the context of the entire system or solution. Generally, there are two types of high availability deployment options for Exchange 2007:
- Single datacenter deployments with redundancy that can
automatically recover from some failures after a short outage. In
the event of a site failure, a single datacenter solution relies on
disaster recovery procedures to return to operating status.
- Multiple datacenter deployments with redundancy that can
automatically recover from most individual failures. A multiple
datacenter solution allows an organization to survive a datacenter
failure without resorting to disaster recovery procedures. Failures
that are not recoverable, such as a total site failure, require
manual intervention for recovery.
Both of these deployment options are discussed in greater detail later in this topic.
Single Datacenter Configurations
Single datacenter configurations for the Unified Messaging, Hub Transport, Client Access, and Edge Transport server roles all involve similarly configured, redundant servers. For Mailbox servers, there are three high availability configurations that provide data and service availability within a single datacenter: SCC, CCR, and local continuous replication (LCR). The following figure illustrates a general deployment for a fully redundant single datacenter configuration.
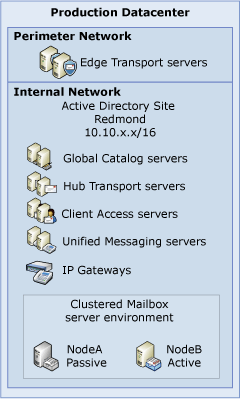
In the preceding figure, the redundancy configuration for the Mailbox server role is abstracted. That is because there are several options available to an organization, including a variety of configurations using SCC and CCR.
Single Copy Clusters
The shared storage cluster configuration in Exchange 2007 is called a single copy cluster (SCC). An SCC uses the Cluster service and shared storage to host a clustered mailbox server. A clustered mailbox server is a logical computer that moves between physical nodes over the course of its lifetime. This is made possible by the Cluster service's ability to create and manage a floating network identity. The floating network identity is used as the clustered mailbox server’s network identity. Exchange Setup automatically creates this network identity using the host name and the IP address provided by the administrator. The floating network identity moves between the nodes in the cluster, based on node availability and maintenance needs. These mechanisms allow users to access their mailbox data if the storage is available and at least one of the two nodes is operational. To make failure recovery work, Exchange and the Cluster service work together to bring the clustered mailbox server online on an available node after a failure.
The following are several key improvements in Exchange 2007 over the shared storage clustering present in previous releases of Exchange Server:
- Only the Mailbox server role is cluster-aware, and it is the
only role that can be installed in a failover cluster.
- Out-of-the-box failover behavior has been optimized to fail
over only when there is a high probability that a failover will
improve availability. Only a complete node failure, or a node's
inability to communicate with clients, causes a failover.
- Most of the administration has been moved out of Cluster
Administrator and into Exchange tools, such as the Exchange
Management Shell. This reduces the learning curve for SCC
administrators.
- Clustered mailbox server installation has been integrated into
Setup, providing the same experience as a stand-alone
installation.
The following figure depicts a typical configuration for an SCC. An SCC supports up to eight node clusters that have at least one passive node.
Figure 2 Basic architecture of a single copy cluster
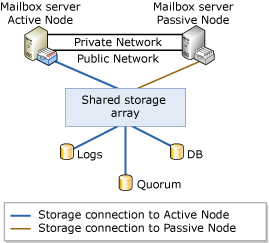
In the preceding figure, the two nodes are joined in a failover cluster. A shared disk is used by the cluster to manage the cluster quorum resource, which is represented by disk Quorum. The active node currently owns the disk resources that house the clustered mailbox server's logs and database files. This ownership is illustrated by the blue lines from the active node to the disks. In this configuration, the disks are accessible by the active node but not simultaneously by the passive node.
The active and passive nodes are connected by at least two networks (private and mixed). Only one of the two networks is used for client communication (the mixed network). The Cluster service regularly checks the communication health of both networks.
For more information about SCC, see Single Copy Clusters.
Cluster Continuous Replication
As its name implies, a single copy cluster contains a single copy of the mailbox data. Failure of the storage hosting the mailbox data does not result in automatic recovery. In fact, such a failure would typically result in an extended outage and data loss. The improvements in SCC over previous cluster solutions address much of the feedback provided by customers on the previous high availability solutions. However, SCC still has the complexity that comes with using shared storage. It has at least two single points of failure out of the box: the single quorum disk and the single copy of the Exchange data. In Exchange 2007, there is a second type of high availability configuration that provides complete redundancy without requiring hardware from the Cluster Solutions category of the Windows Server Catalog of Tested Products. This solution is called cluster continuous replication (CCR).
CCR uses built-in asynchronous log shipping to replicate mailbox data between two servers in a failover cluster. The integration of replication and clustering yields a solution that has no single point of failure and provides automatic recovery from server failures. In addition, it eliminates the need for shared storage, thereby reducing deployment costs and complexity. CCR only supports two-node clusters and only two copies of the data (the active copy and the passive copy). The following figure depicts a typical CCR environment.

Two significant changes illustrated in the preceding figure are the lack of a shared quorum disk and the presence of a file share on a third computer outside of the cluster. The file share is part of new cluster quorum capabilities that are introduced with the update described in Microsoft Knowledge Base article 921181, An update is available that adds a file share witness feature and a configurable cluster heartbeats feature to Windows Server 2003 Service Pack 1-based server clusters. The update enables the Cluster service to use a quorum resource that uses a file share instead of a voter node in the cluster. Without the update, the only quorum options are to use either a shared disk or a traditional majority node set configuration, both of which have drawbacks and increase costs:
- Using a shared disk introduces the complexity of shared storage
back into the solution.
- Majority node set quorums require three or more nodes. In this
configuration, an extra node, known as a voter node, is required to
act as a voter node in the cluster.
For more information about CCR, see Cluster Continuous Replication.
Local Continuous Replication
CCR provides full redundancy of data and services, and SCC provides service redundancy. For those organizations that require data redundancy without service redundancy, there is local continuous replication (LCR). LCR is not a clustered solution, and therefore it does not provide service availability. The following figure depicts a typical LCR environment.
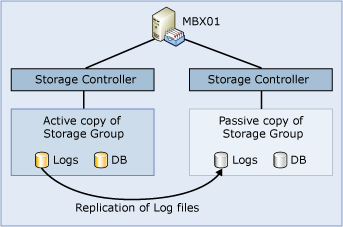
LCR uses the built-in continuous replication technology described in the preceding CCR section to create a second copy (referred to as a passive copy) of a storage group on the local computer. The computer must be a stand-alone (not clustered) Mailbox server. In an LCR environment, the administrator decides which storage groups have a passive copy and configures a second location for the passive copy on the same server.
When using LCR, the administrator must explicitly decide which storage groups have passive copies. Administrators can decide to create a passive copy of an existing storage group, or enable LCR for a new storage group during the creation process. The administrator must configure a second location for the log and database files for those storage groups that are LCR-enabled.
In LCR, activation of the second copy is manual. There is no failover in LCR because failover is a cluster operation, and LCR is not a clustered solution. Instead, the administrator must decide when the active copy is no longer viable and then manually activate the passive copy, which makes it the new active copy. The process to activate the passive copy is simple and quick.
At any time, an administrator can decide to enable LCR and create a passive copy of an existing database, or an administrator can immediately enable LCR when creating a new database. After LCR is enabled, a baseline copy is created using a process called seeding, and then replication (log shipping) is initiated. A best practice is to locate the passive copy on disks or a storage enclosure that is isolated from the active copy. This practice minimizes the chance of multiple simultaneous failures. LCR has a resource impact on the Mailbox server. The Mailbox server is performing all processing associated with continuous replication, and capacity planning for the server must take this into account. Input/output (I/O) load on the active copy is limited because most of the I/O activity for the passive copy is associated with the passive copy's log and database files.
LCR supports backups of the passive copy using Exchange-aware Volume Shadow Copy Service (VSS). When the disk volumes that contain the active copy are appropriately separated from the passive copy, VSS backups without hardware-based VSS support are a good option. Backups from the passive copy offload the backup I/O from the active copy's disk volumes. Because the passive copy does not require a real time response to clients, it can accommodate the costs associated with using a software-based VSS writer. In addition, depending on your capacity planning, it may be practical to extend the backup window on the server with LCR. The key factor is sustaining the backup agent's CPU load throughout the backup window.
The passive copy represents the first line of defense to corruption and data failures. With LCR, the first failure recovery can have a relatively short service level agreement (SLA). A double failure requires restoring from backup. With this model, an SLA for a double failure can be much longer. As a result, a regimen of weekly full backups and daily incremental backups is a viable and recommended strategy. This strategy also reduces the total content moved to backup media.
In summary, LCR is an excellent option for organizations that need fast recovery from data failure or corruption, but can permit server outages for scheduled and unscheduled reasons. LCR provides the following benefits:
- Rapid, two-step recovery from corruption or failure of an
active database.
- Administrator selectivity, which protects the users that need
it most.
- Availability on any size Mailbox server and in all
products.
- Minimal impact to the active database and log I/O.
- Ability to offload backup I/O from the active database and log
volumes.
- Ability to reduce total data moved to backup media, while
extending the backup window.
- Administration abstraction at the Exchange level through the
use of the Exchange Management Console or the Exchange Management
Shell.
For more information about LCR, see Local Continuous Replication.