

Applies to: Exchange Server 2010 SP3, Exchange Server 2010 SP2
Topic Last Modified: 2011-02-02
When planning a highly available Mailbox server and database architecture, design decisions must be considered, such as:
- Will you deploy multiple database copies?
- How many database copies will you deploy?
- Will you have an architecture that provides site
resilience?
- What kind of Mailbox server resiliency model will you
deploy?
- How many Mailbox servers will you deploy?
- How will you distribute database copies?
- What backup model will you use?
- What storage architecture will you use?
Microsoft Exchange Server 2010 enables you to deploy your Mailbox server infrastructure using standalone Mailbox servers or Mailbox servers configured for mailbox resiliency. Mailbox servers configured for mailbox resiliency employ a database availability group (DAG) with multiple database copies efficiently distributed throughout the DAG. By deploying multiple database copies, you can:
- Design a solution that mitigates the most common reason for
using a backup. Database copies provide protection against
hardware, software, and data center failures.
- Increase database sizes up to 2 terabytes because your recovery
mechanism is another database copy and not restoration from
backup.
- Consider storage architecture alternatives to a traditional
RAID configuration like just a bunch of disks (JBOD), if you deploy
three or more database copies. The combination of JBOD and less
expensive disks can result in cost savings for your
organization.
By distributing active databases across all the servers that participate within a DAG, you can maximize the efficiency of your hardware.
For more detailed information, see Planning for High Availability and Site Resilience and Understanding Backup, Restore and Disaster Recovery.
Contents
Planning the Number of Database Copies to Deploy
Planning the Mailbox Server Resilience Model
Planning the Number of Mailbox Servers to Deploy
Planning the Database Copy Layout
Planning the Backup Model Architecture
Planning the Storage Model Architecture
Looking for management tasks related to high availability? See Managing High Availability and Site Resilience.
Planning the Number of Database Copies to Deploy
As discussed in Understanding Mailbox Database Copies, a DAG member can host one copy of each mailbox database, with a maximum of 100 databases per server in the Enterprise Edition of the product (both active and passive copies count toward this limit). This means that there is a limit of 1,600 databases supported by a 16-member DAG (100 database copies per server × 16 servers per DAG ÷ 1 copy per database = 1,600 databases per DAG).
In a high availability configuration, there's no value to deploying a single copy of a database because it doesn't provide data redundancy. You use a formula to determine the number of databases a specific DAG can support. For example, if you choose D to be the number of databases being deployed, C to be the number of copies of each database, and S to be the number of servers, the following applies:
- D × C = total number of database copies in the DAG
- (D × C) ÷ S = database copies per server
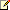 Note: Note: |
|---|
| The resulting number of databases per server must be 100 or less when using the Enterprise Edition and 5 or less when using the Standard Edition. |
For example, let's assume that you have a DAG with 6 servers and 84 mailbox databases, with 3 copies of each database. (Note that 6 servers is an integer multiple of 3 copies.) The following applies:
- 84 databases × 3 copies = 252 databases total
- 252 databases ÷ 6 servers = 42 database copies per server
In another example, you have a DAG with 4 servers and 136 mailbox databases, with 3 copies of each database. The following applies:
- 136 databases × 3 copies = 408 databases total
- 408 databases ÷ 4 servers = 102 database copies per server
Because 102 is greater than 100, the proposed scenario isn't a valid DAG design.
Database Copy Types
There are two types of database copies:
- Highly available database copies
- Lagged database copies
Highly available database copies are copies configured with a replay lag time of zero. As their name implies, highly available database copies are kept up-to-date by the system, can be automatically activated by the system, and are used to provide high availability for mailbox service and data.
Lagged database copies are copies configured to delay transaction log replay for a period of time. Lagged database copies are designed to provide point-in-time protection, which can be used to recover from store logical corruptions, administrative errors (for example, deleting or purging a disconnected mailbox), and automation errors (for example, bulk purging of disconnected mailboxes).
Typically, lagged database copies aren't activated due to the Active Manager Best Copy Selection algorithm. Because lagged database copies are deployed to mitigate operational risks, they shouldn't be activated. If activated and if a mount request is issued, log replay begins, replaying all required log files to bring the database up-to-date and in a clean shutdown state, thus losing the point-in-time capability.
For more information about how to block activation at the Mailbox server level or suspend activation for one or more database copies to prevent a database copy (such as a lagged database copy) from being automatically activated, see Set-MailboxServer and Suspend-MailboxDatabaseCopy.
Site Resilience
Your environment may consist of multiple data centers. As part of your Exchange 2010 design, determine if you will deploy the Exchange infrastructure in a single data center or distribute it across two or more data centers. Your organization's recovery service level agreements (SLAs) should define what level of service is required following a primary data center failure.
If your Exchange deployment will be deployed across multiple data centers to support site resilience goals, consider which user distribution model applies. There are two types of user distribution models, based on the mailbox locality with respect to the data center:
- Active/passive user distribution model
- Active/active user distribution model
If user mailboxes are primarily located in a single data center (or if users access their data through a single data center) and there's an SLA requirement that the users continue to access their data via the primary data center during normal operations, your architecture is an active/passive user distribution model.
If user mailboxes are dispersed across data centers and there's an SLA requirement that the users continue to access their data via the primary data center during normal operations, your architecture is an active/active user distribution model.
In an active/passive user distribution model, you can deploy your architecture as shown in the following figure, where the active mailboxes are hosted from the primary data center, but database copies are deployed in the secondary data center.
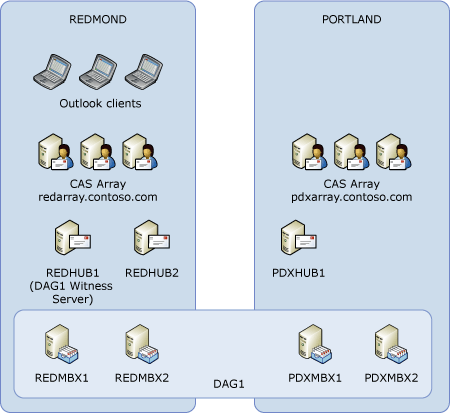
The architecture shown in the following figure could potentially be used for an active/active user distribution model.

However, there's a risk with the architecture shown in the preceding figure. The wide area network (WAN) is a single point of failure for the DAG. The loss of the WAN will result in the loss of quorum for the DAG members in the second data center. In this example, the Windows failover cluster has a total of five votes (four DAG members plus the witness server), requiring three votes to be available at all times for the failover cluster to remain operational. Three of the votes are located in the Redmond data center, and two of the votes are located in the Portland data center. The loss of the WAN connection results in the Portland data center hosting only two of the votes, which isn't sufficient to maintain quorum. The Redmond data center has three votes, and thus can maintain quorum and continue to service the active mailboxes (as long as those three votes are operational).
To mitigate this risk for active/active user distribution models, we recommend deploying two DAGs, as shown in the following figure.
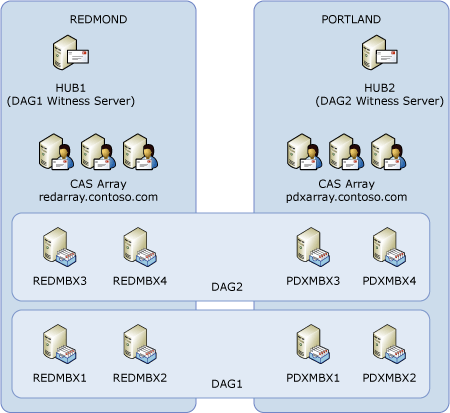
DAG1 hosts the active mailboxes for the Redmond data center and is implemented as an active/passive user distribution model, with passive database copies deployed in the Portland data center. DAG2 hosts the active mailboxes for the Portland data center and is implemented as an active/passive user distribution model, with passive database copies deployed in the Redmond data center.
This architecture can survive the loss of the WAN:
- In the Redmond data center, the Mailbox server members for DAG2
go into a failed state due to loss of quorum, but the active
Mailbox server members for DAG1 remain operational, servicing
users.
- In the Portland data center, the Mailbox server members for
DAG1 go into a failed state due to loss of quorum, but the active
Mailbox server members for DAG2 remain operational, servicing
users.
For more information, see Planning for High Availability and Site Resilience.
Planning the Mailbox Server Resilience Model
A key aspect to Exchange 2010 Mailbox server capacity planning is determining how many database copies you plan to activate on a per-server basis when configured for mailbox resiliency. A range of designs are possible, but two models are recommended, as described in the following sections.
Design for All Database Copies Activated
You can design your server architecture to handle 100 percent of all hosted database copies becoming active. For example, if your server hosts 35 database copies, you design the processor and memory to accommodate all 35 databases being active during the peak period of user activity. This solution is usually deployed in pairs. For example, if deploying four servers, one pair is servers 1 and 2, and the second pair is servers 3 and 4. In addition, when designing for this scenario, you size each server for no more than 40 percent available resources for normal run-time operations.
Of the two models discussed in this topic, this model has a higher server count.
Design for Targeted Failure Scenarios
You can design your server architecture to handle the active mailbox load during the worst failure case you plan to accommodate. There are many factors to consider in this model, including site resiliency; RAID storage vs. JBOD; DAG size; and database copy count. This capacity planning model provides a balance between capital costs, availability, and client performance characteristics.
Assuming the database copies are randomly and evenly distributed:
- Design for automatic, single-member server failure in
two-member or three-member DAG configurations with two highly
available database copies per mailbox database.
- Design for double-member server failure (manual activation
after second failure) in three-member DAG configurations with three
highly available database copies per mailbox database.
- Design for automatic, double-member server failures where the
DAG has four or more members and three or more highly available
database copies per mailbox database.
If you choose this capacity planning model, we strongly recommend that you restrict the number of databases that can be activated per server so that a single server doesn't become overloaded and provide a poor client experience.
You can restrict the number of databases by configuring
the maximum active databases setting. You can configure this limit
in the Exchange Management Shell by running:
Set-MailboxServer -MaximumActiveDatabases. Configure
this limit on each server in the DAG to match the maximum active
databases supported by your deployment.
For more information, see Database Availability Group Design Examples.
Planning the Number of Mailbox Servers to Deploy
When determining the number of Mailbox servers to deploy, use a multiple of the number of database copies being deployed. For example, if you plan to deploy three database copies, start the design with either 3, 6, 9, 12, or 15 servers.
After you determine the starting point for the number of servers within the DAG, scale the DAG members appropriately based on the number of mailboxes, the failure design model, and other design constraints that may either increase or reduce the number of Mailbox servers required.
One design constraint that many organizations have is a maximum number of mailboxes that can be placed on a server. For example, if an organization has 20,000 mailboxes and only 25 percent can be impacted during a failure event, the maximum number of mailboxes that can be deployed on a single server is 5,000. This requires deploying a minimum of four Mailbox servers.
The selected server hardware and storage model may also cause an adjustment to the number of mailboxes or number of database copies you deploy per server, which can affect the total number of Mailbox servers.
Multiple Role Servers vs. Stand-Alone Role Servers
In Exchange Server 2007, the Client Access and Hub Transport server roles are required to be on servers separate from clustered Mailbox servers. In Exchange 2010, clustered Mailbox servers no longer exist so this restriction no longer applies. Client Access and Hub Transport server roles can be hosted on DAG members, providing improved deployment options.
When deploying multiple role servers (Mailbox, Client Access, and Hub Transport server roles on the same server), most architectures are simplified. Other than the Edge Transport and Unified Messaging servers, all Exchange 2010 servers can be identical. These servers can have the same hardware, software installation process, and configuration options. Consistency across servers can simplify the administration of Exchange implementation.
The multiple role server (in high scale environments) provides more efficient use of high-core-count servers, which provide high megacycle capabilities. Each role, when deployed individually, has a recommended maximum of two populated processor sockets. When combining roles, the recommended maximum number of processor sockets is four. Servers can have larger workloads, which can reduce the overall number of servers in an organization. Deploying fewer servers reduces the cost of managing those servers, because the multiple role server changes cost from a recurring operational expense to a one-time capital expense. A reduced server count can result in significant power, cooling, and data center space reductions, which can further reduce recurring operational expenses.
Although the multiple role concept is efficient, stand-alone server roles may still be appropriate. For example, stand-alone role deployments might be appropriate in certain virtualized environments or when certain hardware architectures (for example, a blade server infrastructure where you can't isolate the hardware appropriately) are being utilized.
When deploying multiple role servers, you must design the processor and memory architecture appropriately. From a processor perspective, you should ensure that the Mailbox server role doesn't consume more than 40 percent of the available megacycles during the failure mode, leaving 40 percent for the Hub Transport and Client Access server roles. To ensure that adequate memory is available for all server roles, follow the memory guidance defined in Understanding the Mailbox Database Cache.
For more information, see Understanding Multiple Server Role Configurations in Capacity Planning.
Planning the Database Copy Layout
As part of the high availability design, you need to design a balanced database copy layout. The following design principles should be used when planning the database copy layout:
- Ensure that you minimize multiple database copy failures of a
specific mailbox database by isolating each copy. For example,
don't place more than a single database copy of a specific mailbox
database within the same server rack or in the same storage array.
Otherwise, a rack or array failure will result in the failure of
multiple copies of the same database, which affects the
availability of the database.
- Lay out the database copies in a consistent, distributed way to
ensure that the active mailbox databases are evenly distributed
after a failure. The sum of the activation preferences of each
database copy on any specific server must be equal or close to
equal, because this results in an approximately equal distribution
after failure, assuming replication is healthy and up-to-date.
For more information, see Database Copy Layout Design.
Planning the Backup Model Architecture
Exchange 2010 includes several features and architectural changes that, when deployed and configured correctly, can provide native data protection, which eliminates the need to make traditional backups of your data. Use the following table to decide whether you need to continue utilizing a traditional backup model or whether you can implement the native data protection features in Exchange 2010.
| Issue | Mitigation |
|---|---|
|
Software failures |
Mailbox resiliency (multiple database copies) |
|
Hardware failures |
Mailbox resiliency (multiple database copies) |
|
Site or data center failures |
Mailbox resiliency (multiple database copies) |
|
Accidental or malicious deletion of items |
Single item recovery and deleted item retention with a window that meets or exceeds the item recovery SLA |
|
Physical corruption scenarios |
Single page restore (highly available database copies) |
|
Logical corruption scenarios |
Single item recovery Calendar Repair Assistant Mailbox moves New-MailboxRepairRequest cmdlet Point-in-time backup |
|
Administrative errors |
Point-in-time backup |
|
Automation errors |
Point-in-time backup |
|
Rogue administrators |
Point-in-time backup (isolated) |
|
Corporate or regulatory compliance requirements |
Point-in-time backup (isolated) |
Logical corruption is typically a scenario that requires a point-in-time backup. However, with Exchange 2010, there are several options available that can mitigate the need for a point-in-time backup:
- With single item recovery, if the user changes certain
properties of an item in any mailbox folder, a copy of the item is
saved in the Recoverable Items folder before the modification is
written to the database. If the modification of the message results
in a corrupted copy, the original item can be restored.
- The Calendar Repair Assistant detects and corrects
inconsistencies that occur for single and recurring meeting items
for mailboxes homed on that Mailbox server so that recipients won't
miss meeting announcements or have unreliable meeting
information.
- During mailbox moves, the Microsoft Exchange Mailbox
Replication service detects corrupted items and won't move those
items to the target mailbox database.
- Exchange 2010 Service Pack 1 (SP1) introduces the New-MailboxRepairRequest
cmdlet, which can fix corruptions with search folders, item counts,
folder views, and parent/child folder issues.
A point-in-time backup can be either a traditional backup or a lagged database copy, which both provide the same capabilities. The choice between the two depends on your recovery SLA. The recovery SLA defines the recovery point objective (if a disaster occurs, the data must be restored within a certain timeframe), as well as how long the backups must be retained. If the recovery SLA is 14 days or less, a lagged database copy can be utilized. If the recovery SLA is greater than 14 days, a traditional backup must be used. For the rogue administrator and for corporate or regulatory compliance scenarios, the point-in-time backup typically is maintained separately from the messaging infrastructure and messaging IT staff, which dictates a traditional backup solution.
If you choose to maintain a point-in-time backup, several aspects of the design may change:
- Deploying lagged database copies has storage implications.
Additional space must be allocated for the transaction logs on the
lagged database copy due to the ReplayLagTime settings. In
addition, the placement of the lagged database copy can affect your
storage architecture. (For details, see "Planning the Storage Model
Architecture" later in this topic.)
- Deploying a traditional backup solution has implications on the
logical unit number (LUN) layout, depending on the type of Volume
Shadow Copy Service (VSS) solution, because hardware-based VSS
cloning solutions require two LUNs per database architecture.
Depending on the storage architecture, utilizing a traditional backup solution may require significantly reducing desired user mailbox sizes to meet your backup and restore timeframe SLAs.
When deploying Exchange native data protection, you enable circular logging on the mailbox databases. When enabling circular logging, ensure that sufficient capacity is built into the system so that the solution can survive disaster events that prevent log truncation. At a minimum, you should ensure that there is at least three days of transaction log capacity (excluding lagged copy requirements). For more information about how circular logging functions with continuous replication, see Understanding Backup, Restore and Disaster Recovery.
For additional information about planning backups, see:
Planning the Storage Model Architecture
Exchange 2010 provides flexibility in storage design. Exchange 2010 includes improvements in performance, reliability, and high availability that enable organizations to run Exchange on a range of storage devices. Building on improvements to disk input/output (I/O) introduced in Exchange 2007, the latest version of Exchange requires less storage performance and is more tolerant of storage failures.
Select a storage platform that ensures you're balancing the capacity requirements with the I/O requirements, while ensuring the solution provides acceptable disk latency and a responsive user experience.
RAID or JBOD
Determine whether to implement the storage platform using RAID technology or a JBOD approach (assuming the storage platform allows JBOD configurations). From an Exchange perspective, JBOD means having both the database and its associated logs stored on a single disk. To deploy on JBOD, you must deploy a minimum of three highly available database copies. Utilizing a single disk is a single point of failure, because when the disk fails, the database copy residing on that disk is lost. Having a minimum of three database copies ensures fault tolerance by having two additional copies in the event that one copy (or disk) fails. However, placement of three highly available database copies, as well as the use of lagged database copies, can affect storage design. The following table shows guidelines for RAID or JBOD considerations.
RAID or JBOD considerations
| Data center servers | Two highly available copies (total) | Three highly available copies (total) | Two or more highly available copies per data center | One lagged copy | Two or more lagged copies per data center |
|---|---|---|---|---|---|
|
Primary data center servers |
RAID |
RAID or JBOD (2 copies) |
RAID or JBOD |
RAID |
RAID or JBOD |
|
Secondary data center servers |
RAID |
RAID (1 copy) |
RAID or JBOD |
RAID |
RAID or JBOD |
To deploy on JBOD with the primary data center servers, you need three or more highly available database copies within the DAG. If mixing lagged copies on the same server hosting highly available database copies (for example, not using dedicated lagged database copy servers), you need at least two lagged database copies.
For the secondary data center servers to use JBOD, you should have at least two highly available database copies in the secondary data center. The loss of a copy in the secondary data center won't result in requiring a reseed across the WAN or having a single point of failure in the event the secondary data center is activated. If mixing lagged database copies on the same server hosting highly available database copies (for example, not using dedicated lagged database copy servers), you need at least two lagged database copies.
For dedicated lagged database copy servers, you should have at least two lagged database copies within a data center to use JBOD. Otherwise, the loss of disk results in the loss of the lagged database copy, as well as the loss of the protection mechanism.
For more information, see Understanding Storage Configuration.