

Applies to: Exchange Server 2010 SP3, Exchange Server 2010 SP2
Topic Last Modified: 2012-01-13
When you have multiple Hub Transport servers in your organization, Exchange automatically distributes the mail traffic among all the Hub Transport servers in your organization. The load distribution is successful in distributing the load evenly when all servers are available. However, when one or more servers are unavailable, the load distribution may become uneven among the remaining servers, especially if your organization is distributed across multiple Active Directory sites.
In Microsoft Exchange Server 2010 Service Pack 1 (SP1), several improvements were made to the decision-making mechanism for distributing the load among Hub Transport servers.
Looking for management tasks related to message routing? See Managing Message Routing.
Contents
Exchange Server 2010 RTM Behavior
Exchange 2010 SP1 Improvements
Windows Network Load Balancing or Third-Party Load Balancing Solutions with Transport Servers
Exchange Server 2010 RTM Behavior
In the release to manufacturing (RTM) version of Exchange 2010, when a transport server needs to route several messages to the same destination, the server initially determines the next hop for those messages. If there are multiple target servers for that next hop, it load balances the connection used to deliver messages equally among the target servers using the round robin manner provided by enhanced Domain Name System (DNS). For example, consider a topology where you have two Active Directory sites with three Hub Transport servers in each (as shown in the following figure). When a Hub Transport server in Site A, for example Hub02, needs to send messages to Site B, the next hop for that message is Site B. There are three possible targets in the next hop: Hub04, Hub05, and Hub06. The server will distribute the number of connections evenly across those three targets as shown in the following figure. This action results in an even distribution of messages across the connections over time.
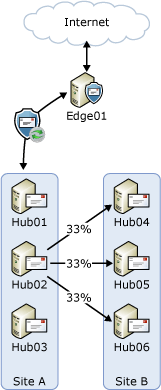
Similarly, the Hub Transport servers in Site B will distribute the number of messages sent to recipients in Site A evenly across Hub01, Hub02, and Hub03. Also, because Edge01 is subscribed to Site A, the targets for the next hop for messages sent to the Internet are Hub01, Hub02, and Hub03.
A problem arises if one or more of the servers are unavailable in the next hop. For example, assume that Hub04 in Site B is unavailable for scheduled maintenance. The servers in Site A don't maintain availability status of each server in Site B. The servers in Site A will distribute the load destined for Site B among the three Hub Transport servers in that site. However, approximately one third of those connections would be sent to Hub04 but won't succeed. These connections will fail over to the next available server, and one of the Hub Transport servers in Site B will process substantially more load than the other server as shown in the following figure.
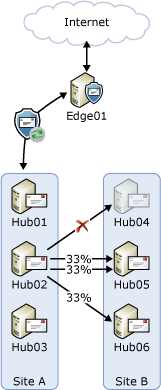
This undesirable behavior may occur whenever there's an unavailable server in the next hop that typically has more than two targets. The next hop could be another Active Directory site as shown in the preceding example, or a connector that has multiple Hub Transport servers listed as the source server (for example, the Send connector to the subscribed Edge Transport server in the topology shown in the preceding figures).
This isn't an issue for mail submissions from Mailbox servers. The mail submission service will detect unavailable Hub Transport servers in a site, and won't attempt to deliver to those servers. In the example shown previously, although one of the Hub Transport servers in Site B may have a heavier load from intersite traffic, the load generated by Mailbox servers in Site B will be evenly split between Hub05 and Hub06.
Exchange 2010 SP1 Improvements
To address the issue described in the previous section, a new component called Healthy Server Selector was added in Exchange 2010 SP1. Healthy Server Selector maintains a list of servers that are unavailable. This list is used by enhanced DNS to filter out any unavailable servers when applying round robin logic for load balancing. To demonstrate how Healthy Server Selector helps with load balancing, consider the problematic condition shown in the preceding figure. In Exchange 2010 SP1, enhanced DNS will first compile the list of potential targets in the next hop, Site B. It will then ask Healthy Server Selector to filter the list. Healthy Server Selector will report that Hub04 for the next hop Site B is unhealthy. Enhanced DNS will remove Hub04 from the list of potential targets for the next hop Site B, and will use round robin load balancing only between Hub05 and Hub06 as shown in the following figure.
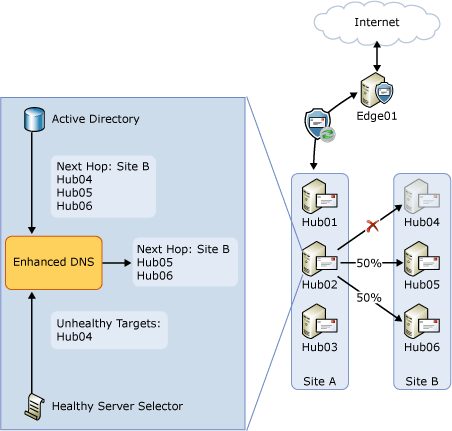
Healthy Server Selector
In its simplest form, Healthy Server Selector tracks servers deemed unhealthy so that those servers aren't included in round robin load balancing. From a Healthy Server Selector perspective, a definition of an unhealthy server is one to which a connection attempt returns any Windows sockets (Winsock) error code.
For each unhealthy server, Healthy Server Selector keeps the following information:
- Server IP address
- Retry count
- Last retry time
Retry Behavior
When a server is marked as unhealthy, Healthy Server Selector will ensure that connections to that specific server are tried again to detect when that server comes online. Healthy Server Selector uses the following settings to determine how frequently connections will be retried to an unhealthy server:
- QueueGlitchRetryInterval and
QueueGlitchRetryCount These settings determine
how many times and at what interval Healthy Server Selector retries
connections to a specific server when it's first marked unhealthy.
These settings are configured in the EdgeTransport.exe.config file.
The default values for these settings are 1 minute and 4 retry
attempts. These values mean that a connection to an unhealthy
server will be attempted every minute four times in a default
configuration.
- TransientFailureRetryInterval and
TransientFailureRetryCount If the unhealthy
server is unavailable, these settings are used by Healthy Server
Selector to determine the frequency of the next set of retry
attempts. These settings are configured for each transport server.
The default values are 5 minutes (10 minutes on an Edge Transport
server) and 6 retry attempts. These values mean that a connection
to an unhealthy server will be attempted every five minutes six
times after the first four minutes in a default configuration.
-
OutboundConnectionFailureRetryInterval If
the unhealthy server is unavailable, Healthy Server Selector will
continue to retry the connection by the frequency specified in this
parameter. This setting is configured for each transport server.
The default value is 10 minutes (30 minutes on an Edge Transport
server). This means that a connection will be attempted to an
unhealthy server every 10 minutes after the first 34 minutes in a
default configuration.
For step-by-step instructions about how to configure these settings, see Configure Message Retry, Resubmit, and Expiration Intervals.
When it's time to retry a connection, Healthy Server Selector allows only one connection attempt to the unhealthy server. If that connection succeeds, the SMTP outbound component will notify Healthy Server Selector that the connection is successful. At that point, Healthy Server Selector removes the server from the list of unhealthy servers.
Healthy Server Selector and Shadow Redundancy
The shadow redundancy component of transport includes a heartbeat feature. The heartbeat is a simple SMTP connection used to query the status of messages previously submitted to a target server. Healthy Server Selector filtering won't prevent the Shadow Redundancy Manager from issuing heartbeat connection attempts. If a server has shadow messages that were submitted to a server that's unhealthy, it will attempt to make heartbeat connections to that server. If a heartbeat connection succeeds to an unhealthy server, that target server is immediately removed from the list of unhealthy servers by Healthy Server Selector.
To learn more about shadow redundancy and the heartbeat, see Understanding Shadow Redundancy.
Diagnostic Information
In Exchange 2010 SP1, the connectivity logs include diagnostic information for Healthy Server Selector and the enhanced load balancing features. When a server is added to the unhealthy servers list by Healthy Server Selector, the event is logged in the connectivity log. To locate this event, search for the phrase MarkedUnhealthy in the connectivity log. On the line that contains this phrase, you can find the following information:
- Target host IP address
- Target host fully qualified domain name (FQDN)
- Winsock error received
- Status:
MarkedUnhealthy
- Current failure count
- Next retry time
From this entry, you can identify the reason for the failure by evaluating the Winsock error code. For a complete list of Winsock error codes and their definitions, see Windows Sockets Error Codes.
You can also determine how many connection attempts have failed and the next scheduled retry attempt to the target server by analyzing the Current Failure Count and Next Retry Time fields.
You must have connectivity logging enabled on your transport servers to be able to see this diagnostic information. Connectivity logging is disabled by default on Hub Transport and Edge Transport servers. For more information about configuring connectivity logging, see Configure Connectivity Logging.
Windows Network Load Balancing or Third-Party Load Balancing Solutions with Transport Servers
As discussed earlier in this topic, Exchange 2010 automatically load balances all intra-organization message traffic between Edge Transport, Hub Transport, and Mailbox servers using enhanced DNS. However, this functionality doesn't cover the load balancing of messages received from non-Exchange sources such as external mail servers, third-party anti-spam or antivirus solutions, any internal mail servers outside your Exchange organization, line-of-business (LOB) applications, and POP-based or IMAP-based e-mail clients.
If you have one or more of these mail sources, you may choose to load balance incoming SMTP traffic using a unified SMTP namespace (such as smtp.contoso.com) that distributes external e-mail messages across the transport servers within the organization. Windows Network Load Balancing (NLB) or a hardware-based load balancing solution from a third-party vendor are both supported. For a list of load balancers that have been tested by the vendor and reviewed by Microsoft to meet Exchange 2010 requirements, see Microsoft Unified Communications Load Balancer Deployment.
 Important: Important: |
|---|
| Using a load balancing solution to handle message traffic between the Exchange servers in your organization isn't supported. You must exclude message traffic between Exchange servers from any load balancing solution you deploy in your environment. |
Load Balancing Inbound Internet Messages Among Your Edge Transport Servers
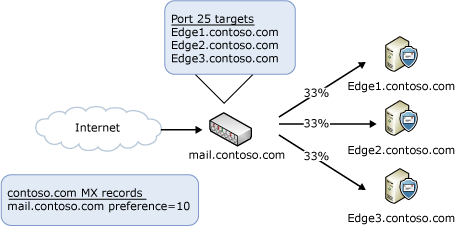
The most common situation is handling incoming messages from the Internet. You don't need to deploy a load balancing solution to distribute the load across your Edge Transport servers. You can accomplish this by using DNS round robin and mail exchange records (MX records) that have the same preference value, as shown in the following figure.
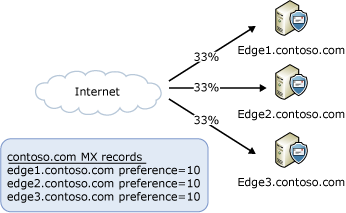
If you choose to use Windows NLB or a hardware load balancing solution to distribute incoming Internet messages, you need to publish a single MX record that points to your load balancing solution. The load balancer will distribute incoming messages to all the Edge Transport servers listed in its configuration, as shown in the following figure.
Load Balancing Non-Exchange Messages Among Your Hub Transport Servers
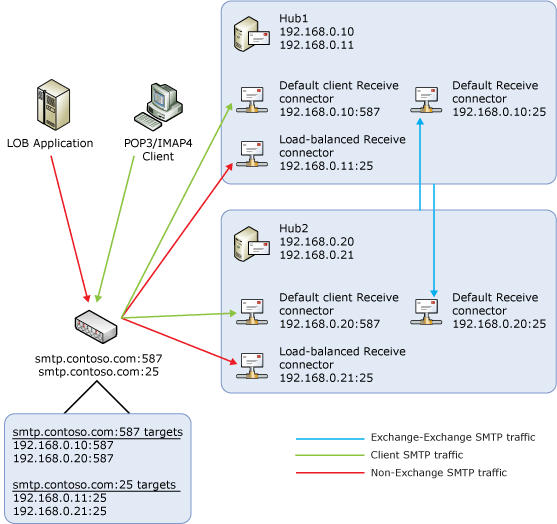
Exchange 2010 uses Receive connectors to accept incoming messages. By default, when an Exchange 2010 Hub Transport server receives an e-mail message via SMTP over TCP port 25, it's processed by the Receive connector named Default Receive connector.
When a POP or IMAP client submits an e-mail message to an Exchange 2010 Hub Transport server, the message is submitted over TCP port 587 by default. This means e-mail messages submitted from POP or IMAP clients are processed by a separate Receive connector named Default Client Receive connector.
If you plan on placing a load balancing solution in front of your Hub Transport servers, you should create a separate Receive connector for that purpose and make sure that only traffic processed by that particular connector is subject to load balancing. This can be achieved by adding an additional IP address to the Hub Transport server and associating this IP address with the new Receive connector. In addition, the Exchange Server authentication option should be disabled on the Receive connector to ensure Exchange traffic doesn’t route over it. The following figure shows a configuration where a load balancer is used to distribute messages received from POP3 or IMAP4 clients and non-Exchange SMTP servers among two Hub Transport servers.
Windows Network Load Balancing
Windows NLB is the most common software load balancer used for Exchange servers. There are some limitations associated with deploying Windows NLB with Exchange 2010 Hub Transport servers:
- Windows NLB can't be used on Exchange servers where the Hub
Transport and Mailbox server roles coexist and the server also
participates in a database availability group (DAG).
This is because the Windows NLB feature is incompatible with Windows failover clustering. If you use an Exchange 2010 DAG and you want to use Windows NLB, you need to have the Hub Transport server role and the Mailbox server role running on separate computers. In addition, Windows NLB impacts message routing when the DAG member and Hub Transport server role coexist on the same server. To learn more, see Hub Transport and Mailbox Server Roles Coexistence When Using DAGs.
- We don't recommend putting more than eight Hub Transport
servers in an array that's load balanced by Windows NLB. If you
need to load balance more than eight Hub Transport servers, you
should deploy a hardware-based solution.
- Windows NLB doesn't detect service outages.
It only detects server outages by IP address. If the Exchange Transport service fails, but the server is still functioning, Windows NLB won’t detect the failure and will still route incoming e-mail messages to that Hub Transport server. Manual intervention is required to remove the Hub Transport server experiencing the outage from the load balancing pool.
- Windows NLB configuration can result in port flooding, which
can overwhelm networks.
This is because Windows NLB has been designed in such a way that it simultaneously delivers all incoming client packets to all switch ports. Although this behavior enables Windows NLB to deliver very high throughput, it may cause high switch occupancy.
For detailed steps about configuring Windows NLB, see Configure Windows Network Load Balancing for Hub Transport Servers.
Hardware Load Balancing
If you have more than eight Hub Transport servers for which you want to load balance non-Exchange message traffic, you need a more scalable load balancing solution. Although there are robust software load balancing solutions available, a hardware load balancing solution provides the most capacity.
Unlike Windows NLB, which only detects server outages by IP address, a hardware load balancer can be configured to detect the failure of the Exchange Transport service and can route incoming e-mail messages to other Hub Transport servers without any manual intervention.
For detailed steps about configuring a hardware load balancing solution, see Configure Hardware Load Balancing for Hub Transport Servers.