

Applies to: Exchange Server 2007 SP3, Exchange Server
2007 SP2, Exchange Server 2007 SP1, Exchange Server 2007
Topic Last Modified: 2008-11-19
Exchange mailbox databases and the queue on Hub Transport servers and Edge Transport servers utilize the Extensible Storage Engine (ESE) database. ESE is a multi-user, indexed sequential access method (ISAM) table manager with full data manipulation language (DML) and data definition language (DDL) capability. ESE allows applications to store records and create indexes to access those records in different ways.
There are two versions of ESE:
- ESENTl The database engine for Active
Directory and many Microsoft Windows components. Unlike other
versions of ESE (which use 5-MB log files and 4-KB page sizes), the
Active Directory implementation of ESENT uses 10-MB log files and
8-KB pages.
- ESE98 The database engine in Exchange
2000 Server, Exchange Server 2003, and Exchange Server 2007.
- ESE was previously known as Joint Engine Technology (JET) Blue.
JET Blue is not the same as the version of JET found in Microsoft
Access (known as "JET Red").
 Transactions
Transactions
ESE is a sophisticated, transaction-based database engine. A transaction is a series of operations that are treated as an atomic (indivisible) unit. All operations in a transaction are either completed and permanently saved, or no operations are performed. Consider, for example, the operations involved when moving a message from the Inbox to your Deleted Items folder. The message is deleted from one folder, added to another folder, and the folder properties are updated. If a failure occurs, you do not want two copies of the message, no copies at all, or folder property values (such as item count) that are inconsistent with the actual folder contents.
To prevent problems such as this, ESE bundles operations inside a transaction. ESE makes sure that none of the operations are permanently applied until the transaction is committed to the database file. When the transaction is committed to the database file, all the operations are permanently applied.
If a server stops responding, ESE also handles automatic recovery when you restart the server and rolls back any uncommitted transactions. If ESE fails before a transaction is committed, the entire transaction is rolled back, and it is as if the transaction never occurred. If ESE stops responding after the transaction is committed, the entire transaction is persisted, and the changes are visible to clients.
ACID Transactions
Transactions such as those listed in the previous section are generally referred to as ACID transactions. ACID is an acronym for the following attributes:
- Atomic This term indicates that a
transaction state change is all or none. Atomic state changes
include database changes, and messages and actions on
transducers.
- Consistent This term indicates that a
transaction is a correct transformation of the state. The actions
taken as a group do not violate any one of the integrity
constraints associated with the state. This requires that the
transaction be a correct program.
- Isolated This term indicates that even
though transactions run at the same time, it appears to each
transaction (t), that other transactions executed either
before t or after t, but not both.
- Durable Committed transactions are
preserved in the database, even if the system stops responding.
The Version Store
The version store enables ESE to track and manage current transactions. Therefore, ESE can pass the Isolated and Consistent parts of the ACID test. The version store maintains an in-memory list of modifications that were made to the database.
The version store is used in the following situations:
- Rollback If a transaction must roll
back, it examines the version store to get the list of operations
it performed. By performing the inverse of all the operations, the
transaction can be rolled back.
- Write-conflict detection If two
different sessions try to modify the same record, the version store
notices and rejects the second modification.
- Repeatable reads When a session starts
a transaction, it always encounters the same view of the database,
even if other sessions modify the records that it is viewing. When
a session reads a record, the version store is consulted to
determine what version of the record the session should view.
Repeatable reads provide an isolation level in which, after a
client starts a transaction, it views the state of the database as
it was when the transaction began, regardless of modifications made
by other clients or sessions. Repeatable reads are implemented by
using the version store. With an in-memory list of modifications
made to the database, it can be determined what view of a record
any particular session should view.
- Deferred before-image logging This is a
complex optimization that lets ESE log less data than other
comparable database engines.
Snapshot Isolation
After a transaction starts, ESE guarantees that the session views a single, consistent image of the database, as it exists at the start of its transaction, plus its own changes. Because other sessions can also modify the data and commit their transactions, these changes are invisible to any transaction that started before the commit. A user can modify a record only if that user is viewing the latest version. Otherwise, the update fails with JET_errWriteConflict. Versions earlier than the latest transaction are automatically discarded.
ESE features a transaction isolation level called Snapshot Isolation. Snapshot Isolation level allows users to access the last committed row using a transitionally consistent view of the database. Snapshot Isolation is a concurrency control algorithm that was first described in the paper A Critique of ANSI SQL Isolation Levels. Snapshot Isolation is implemented by ESE by using repeatable reads.
ESE Database Structure
All data inside the rich-text database file is stored in B+trees. The "B" in B+tree, means "balanced." "Tree" refers to an arrangement that is similar to a folder structure on a file system, where a root is the parent of items (database pages) that in turn are parents to additional items. B+trees are designed to provide fast access to data on disk. Because reading from and writing to a disk is much slower than performing those operations in memory, a B+tree is divided into 8-KB pages. This enables ESE to get the data it needs by using the minimum number of Disk I/Os. An ESE database can contain up to 2^31 (2 to the 31st power) 8-KB pages for a total maximum database size of approximately 16 terabytes. In reality, database size is limited only by your ability to back up, restore, and perform other maintenance operations on the database (such as offline defragmentation and database repairs) in a timely manner.
Database Pages
The page size in ESE is defined by the application that uses it. For example, ESE98 (Exchange 2000 Server and Exchange Server 2003) use four KB pages, whereas ESENT (Active Directory) uses eight KB pages. Each of these four KB or eight KB pages contains pointers to other pages or to the actual data that is being stored in the B+tree. The pointer and data pages are intermixed in the file.
To increase performance wherever possible, pages are cached in a memory buffer for as long as possible. This reduces the need to go to disk. Each page starts with a 40-byte page header, which includes the following values:
- pgnoThis This value indicates the page
number of the page.
- DbtimeDirtied This value indicates the
Dbtime the page was last modified.
- pgnoPrev This value indicates the page
number of the adjacent left page on the leaf.
- pgnoNext This value indicates the page
number of the adjacent right page on the leaf.
- ObjidFDP This value indicates the
Object ID of a special page in the database, referred to as Father
of the Data Page (FDP), which indicates which B+tree this page
belongs to. The FDP page is used during repair.
- cbFree This value indicates the number
of bytes available on the page.
- cbUncommittedFree This value indicates
the number of uncommitted bytes available (bytes that are free but
available for reclaim by rollback) on the page.
- ibMicFree This value indicates the page
offset for the next available byte at the top of the page.
ECC Checksum
Error Correcting Code (ECC) Checksum enables the correction of single-bit errors in database pages (in the .edb file).
It consists of two 32-bit checksums. The first is an XOR checksum in which the page number is used as a seed in the calculation. The second 32-bit checksum is an ECC checksum, which allows for the correction of single-bit errors on the page.
Database Consistency and -1018
Errors
When a page is read, ESE examines a flag on the page to see whether the page has the current checksum format. The appropriate checksum is then calculated. If there is a checksum mismatch with the current format checksum, ESE tries to correct the error. If the error cannot be automatically corrected, Exchange reports a -1018 error.
The Exchange store might be responsible for self-generating a -1018 error, if the Exchange store does one of the following:
- Constructs a page that has the wrong checksum.
- Constructs a page correctly, but tells the operating system to
write the page in the wrong location.
If a system administrator encounters a -1018 error or runs diagnostic hardware tests against the server and these tests report no issues, the administrator might conclude that Exchange must be responsible for the issue, because the hardware passed the initial analysis.
Frequently, additional investigation by Microsoft or hardware vendors uncovered subtle issues in hardware, firmware, or device drivers that are actually responsible for damaging the database file.
Ordinary diagnostic tests might not detect all the transient faults for several reasons. Issues in firmware or driver software might fall outside the capabilities of diagnostic programs. Diagnostic tests might be unable to adequately simulate long run times or complex loads. Also, the addition of diagnostic monitoring or debug logging might change the system enough to prevent the issue from appearing again.
The simplicity and stability of the Exchange mechanisms that generate checksums and write pages to the database file suggest that a -1018 error is probably caused by something other than Exchange. The checksum and incorrect page detection mechanisms are simple and reliable, and have remained fundamentally the same since the first Exchange release, except for minor changes to adapt to database page format changes between database versions.
A checksum is generated for a page that is about to be written to disk, after all other data is written to the page, including the page number itself. After Exchange adds the checksum to the page, Exchange instructs the Microsoft Windows Server operating system to write the page to disk by using standard, published Windows Server APIs.
The checksum might be generated correctly for a page, but the page might be written to the wrong location on the hard disk. This can be caused by a transient memory error, such as a "bit flip." For example, suppose Exchange constructs a new version of page 70. The page itself does not experience an error, but the copy of the page number that is used by the disk controller or by the operating system is randomly changed. This problem can occur if 70 (binary 1000110) has been changed to 6 (binary 000110) by an unstable memory cell. The page's checksum is still correct, but the location of the page in the database is now wrong. Exchange reports a -1018 error for the page when it detects that the logical page number does not match the physical location of the page.
Another kind of page numbering error (caused by Exchange) may occur if Exchange writes the wrong page number on the page itself. But this causes other errors, not the -1018 error. If Exchange writes 71 on page 70, and then performs the checksum on the page correctly, the page is written to location 71 and passes both the page number and checksum tests.
Frequently, a single -1018 error that is reported in an Exchange database does not cause the database to stop or result in a symptom other than the presence of the -1018 error itself. The page might be in a folder that is infrequently accessed (for example, the Sent or Deleted Items folders), or in an attachment that is seldom opened, or even empty.
Even though a single -1018 error is unlikely to cause extensive data loss, -1018 errors are still cause for concern because a -1018 error is proof that your storage system did not reliably store or retrieve data at least one time. Although the -1018 error might be a transient issue that never occurs again, it is more likely that this error is an early warning of an issue that will become progressively worse. Even if the first -1018 error is on an empty page in the database, you cannot know which page might be damaged next. If a critical global table is damaged, the database might not start, and database repair might be partly or completely unsuccessful.
After a -1018 error is logged, you must consider and plan for the possibility of imminent failure or additional random damage to the database, until you find and eliminate the root cause.
Database Tree Balancing
One of the primary functions of ESE is to keep the database tree balanced at all times. The process of balancing the tree is finished when all the pages are either split or merged. As you can see in the following figure, the same number of nodes is always at the root level of the tree as is at the leaf level of the tree. Therefore, the tree is balanced.
Balanced tree
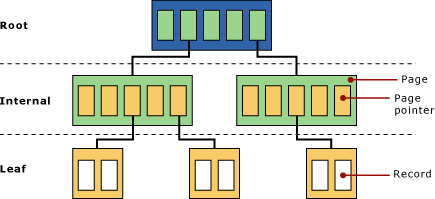
From an ESE perspective, a database table is a collection of B+trees. Each table consists of one B+tree that contains the data, although there can be many secondary index B+trees used to provide different views of the data. If a column or field in a table becomes too wide to store in the B+tree, it is divided to a separate B+tree, named the long-value tree.
The definition of these tables and their associated B+trees is stored in another B+tree, named the system catalog. Loss of the system catalog is a serious problem. Therefore, ESE keeps two identical copies of this B+tree in each database.
Split
When a page becomes almost full, about half the data is put on a secondary page and an extra key is put in the secondary page's parent page. This process is performed unless the parent page is also full. In this event, the parent page is split, and a pointer is added to this page's parent page. Ultimately, every pointer page up to the root block might need to be split. If the root block needs to be split, an additional level of pages is inserted into the tree. Figuratively speaking, the tree grows in height.
Merge
When a page is almost empty, it is merged with an adjacent page, the pointers in the parent page are updated, and if it is required, the page is merged. Ultimately, if every pointer page up to the root block is merged, the tree shrinks in height. To obtain to a leaf (data), ESE starts at the root node and follows the page pointers until it gets to the desired leaf node.
Fan-Out
The tree structure of an ESE B+tree has very high fan-out. High fan-out means ESE can reach any piece of data in a 50 GB table with no more than four disk reads (three pointer pages and the data page itself). ESE stores over 200 page pointers per four KB page, enabling ESE to use trees with a minimal number of parent/child levels (also called shallow trees). ESE also stores a key of the current tree, which enables ESE to quickly search down the current tree. The preceding diagram is a tree with three parent/child levels; a tree with four parent/child levels can store many gigabytes of data.
Indexes
A traditional B+tree is indexed in only one particular way. It uses one key, and the data must be retrieved using that key. For example, the records in the messages table are indexed on a message's unique identifier, called the message transfer service (MTS)-ID. However, a user probably wants to view the data in the messages table ordered in a more user friendly format.
Indexes, or more specifically, secondary indexes, are used to retrieve the data. Each secondary index is another B+tree that maps the chosen secondary key to the primary key. This makes B+trees small compared to the data they index.
To understand how a secondary index is used, consider what occurs when a user changes the way messages are presented in a messaging folder. If you change your folder view in Outlook so that subject, instead of received time, orders the view, Outlook causes the store and ESE to build a new, secondary index on your message folder table.
When you change views on a large folder for the first time, you will experience a delay. If you look closely at the server, you see a small spike in disk activity. When you switch to that view again, the index is already built, and the response is much quicker.
The Microsoft Exchange Information Store services' secondary index B+trees live for eight days. If they are not used, the Microsoft Exchange Information Store service deletes them as a background operation.
Long-Values
A column or a record in ESE cannot span pages in the data B+tree. There are values (such as PR_BODY, which is the message body of a message) that break the 4KB boundary of a page. These are referred to as long-values (LV). A table's long-value B+tree is used to store these large values.
If a piece of data is entered in an ESE table, and it is too large to go into the data B+tree, it is divided into four KB sized pages and stored in the table's separate long-value B+tree. The record in the data B+tree contains a pointer to the long-value. This pointer is called the long-value ID (LID) and means that the record has a pointer to LID 256.
Record Format
A collection of B+trees represents a table, and a table is a collection of rows. A row is also called a record. A record consists of many columns. The maximum size of a record, and therefore the number of columns that appear in a single record, is governed by the database page size, minus the size of the header. ESE has a four KB-page size. Therefore, the maximum record size is approximately 4,050 bytes (4,096 bytes, minus the size of the page header).
Column Data Types
Each column definition must specify the data type that is stored in the column. ESE supports the data types described in the following table.
Extensible Storage Engine column data types
| Column Data Types | Description |
|---|---|
|
Bit |
NULL, 0, or non-0 |
|
Unsigned Byte |
1-byte unsigned integer |
|
Short |
2-byte signed integer |
|
Unsigned Short |
2-byte unsigned integer |
|
Long |
4-byte signed integer |
|
Unsigned Long |
4-byte unsigned integer |
|
LongLong |
8-byte signed integer |
|
Currency |
8-byte signed integer |
|
IEEE Single |
4-byte floating-point number |
|
IEEE Double |
8-byte floating-point number |
|
Date Time |
8-byte date-time (integral date, fractional time) |
|
GUID |
16-byte unique identifier |
|
Binary |
Binary string, length <= 255 |
|
Text |
ANSI or Unicode string, length <= 255 bytes |
|
Long Binary |
Large value binary string, length < 2 GB |
|
Long Text |
Large value ANSI or Unicode string, length < 2 GB |
The column data types fall into two categories. The first category is fixed and variable columns. The second category is tagged columns. Each column is defined as a 16-byte FIELD structure, plus the size of the column name.
When a table is created in an ESE database, the table is defined by using an array of FIELD structures. This array identifies the individual columns in the table. Within this array, each column is represented through an index value, called the column ID. This is similar to an ordinary array in which you can reference array members by ID, such as array[0], array[1], and so on. Columns are quickly accessed by ID, but a search by column name requires a linear scan through the array of FIELD structures.
Fixed and Variable Columns
Fixed columns contain a fixed data length. Each record occupies a defined amount of record space, even if no value is defined. Data type IDs 1 to 10 can be defined as fixed columns. Each table can define up to 126 fixed columns (column ID 1 to 127).
Variable columns can contain up to 256 bytes of data. An offset array is stored in the record with the highest variable column set. Each column requires two bytes. Data type Ids 10 and 11 can be defined as variable columns. Each table can define up to 127 variable columns (column ID 128 to 256).
Tagged Columns
ESE defines columns that occur rarely or have multiple occurrences in a single record as tagged columns. An undefined tagged column incurs no space overhead. A tagged column can have repeated occurrences in the same record. If a tagged column is represented in a secondary index, each distinct occurrence of the column is referenced by the index.
Tagged columns can contain an unlimited, variable length of data. The column ID and length are stored with the data. All data types can be defined as tagged columns. Each table can define up to 64,993 tagged columns.