

Базы данных почтовых ящиков сервера Exchange Server 2007 и очередь на транспортных серверах-концентраторах и пограничных транспортных серверах используют базу данных расширенного обработчика хранилищ (ESE). ESE представляет собой многопользовательский диспетчер таблиц, использующий технологию индексированного последовательного метода доступа (ISAM), с полноценными возможностями языка обработки данных DML и языка описания данных DDL. ESE позволяет приложениям хранить записи и создавать индексы для доступа к этим записям различными способами.
Существует две версии ESE:
- ESENTl Ядро СУБД для Active Directory и
многих компонентов Microsoft Windows. В отличие от других версий
ESE (использующих файлы журнала размером 5 МБ и страницы
размером 4 КБ), в реализации ESENT для Active Directory
используются файлы журнала размером 10 МБ и страницы размером
8 КБ.
- ESE98 Ядро СУБД для серверов Exchange
2000 Server, Exchange Server 2003 и Exchange Server 2007.
- ESE ранее назывался JET (Joint Engine Technology) Blue. JET
Blue отличается от версии JET, используемой в Microsoft Access
(известной как «JET Red»).
 Транзакции
Транзакции
ESE представляет собой усовершенствованное ядро СУБД на основе транзакций. Транзакция — это серия операций, рассматриваемых как атомарная (неделимая) единица. В транзакции выполняются и сохраняются либо все операции, либо ни одна из операций. Рассмотрим, к примеру, операции, выполняемые при перемещении сообщения из папки «Входящие» в папку «Удаленные». Сообщение удаляется из одной папки, добавляется в другую папку, а свойства папок обновляются. В случае сбоя не должно возникнуть ситуаций, в которых имеются две копии сообщения или ни одной копии сообщения, либо ситуации, в которой свойства папки (например количество элементов) не соответствуют фактическому содержимому папки.
Для предотвращения подобных проблем ESE объединяет операции в единую транзакцию. ESE гарантирует, что ни одна из операций не будет окончательно применена, пока в файле базы данных не будет завершена транзакция. После завершения транзакции в файле базы данных все операции применяются окончательно.
В случае отсутствия ответа сервера ESE выполняет автоматическое восстановление при перезагрузке сервера и откатывает назад все незавершенные транзакции. В случае сбоя ESE до завершения транзакции вся транзакция откатывается, а система переходит в исходное состояние, как будто транзакция никогда не выполнялась. В случае отсутствия ответа со стороны ESE после завершения транзакции, результаты работы всей транзакции сохраняются, а изменения становятся видимыми клиентам.
Транзакции ACID
Транзакции, подобные перечисленным выше в предыдущем разделе, обычно называются транзакциями ACID. Аббревиатура ACID составлена из первых букв перечисленных ниже атрибутов.
- Атомарный (Atomic) Этот термин
указывает на то, что состояние транзакции изменяется полностью либо
не изменяется совсем. Атомарные изменения состояния включают
изменения базы данных, а также сообщения и действия над
преобразователями.
- Согласованный (Consistent) Этот термин
указывает на то, что транзакция является правильным преобразованием
состояния. Группа действий не нарушает ни одно из ограничений
целостности, связанных с состоянием. Для этого требуется, чтобы
транзакция была правильной программой.
- Изолированный (Isolated) Этот термин
указывает на то, что даже при одновременном выполнении транзакций
для каждой транзакции (Т) другие транзакции выполняются либо
до транзакции Т, либо после транзакции Т, но не
одновременно.
- Долговечный (Durable) Завершенные
транзакции сохраняются в базе данных даже в случае сбоя
системы.
Хранилище версий
Хранилище версий позволяет ESE отслеживать текущие транзакции и управлять ими. Таким образом, ESE может пройти компоненты Isolated (изолированный) и Consistent (согласованный) ACID-теста. Хранилище версий поддерживает в памяти список изменений, внесенных в базу данных.
Хранилище версий используется в указанных ниже ситуациях.
- Откат транзакции Если необходимо
откатить транзакцию, из хранилища версий извлекается список
выполненных транзакцией операций. Транзакцию можно откатить путем
отмены всех операций.
- Обнаружение конфликтов записи Если два
различных сеанса пытаются изменить одну и ту же запись, хранилище
версий обнаруживает и отклоняет вторую попытку изменения.
- Повторные операции чтения Когда сеанс
начинает транзакцию, состояние базы данных для него остается
неизменным, даже если другие сеансы изменяют просматриваемые данным
сеансом записи. Когда сеанс выполняет чтение записи, он обращается
к хранилищу версий, чтобы определить отображаемую для данного
сеанса версию записи. Повторные операции чтения обеспечивают
уровень изоляции, при клиент, начав транзакцию, видит базу данных в
том состоянии, в котором она находилась в момент начала транзакции,
независимо от изменений, внесенных другими клиентами или сеансами.
Повторные операции чтения реализованы с помощью хранилища версий.
Благодаря хранящемуся в памяти списку изменений, внесенных в базу
данных, можно определить вид записи, который необходимо представить
для просмотра конкретному сеансу.
- Отложенная запись в журнал исходного вида
записи Это сложный метод оптимизации,
позволяющий ESE записывать в журнал меньше данных, чем записывают
другие аналогичные ядра СУБД.
Изоляция моментального
снимка
После начала транзакции ESE гарантирует, что сеансу представляется единый, согласованный образ базы данных, существующий на момент начала транзакции, с учетом изменений, внесенных самой транзакцией. Поскольку другие сеансы также могут изменять данные и выполнять собственные транзакции, эти изменения невидимы для остальных транзакций, начавшихся до завершения транзакции. Пользователь может изменять запись только в том случае, если он просматривает последнюю версию. В противном случае возникает ошибка обновления с кодом JET_errWriteConflict. Версии, предшествующие последней транзакции, автоматически отбрасываются.
ESE представляет уровень изоляции транзакций, называемый изоляцией моментального снимка. Уровень изоляции моментального снимка позволяет пользователям получить доступ к последней записанной строке с помощью промежуточного согласованного представления базы данных. Изоляция моментального снимка представляет собой алгоритм контроля совместного доступа, впервые описанный в статье Критика уровней изоляции ANSI SQL (на английском языке). Изоляция моментального снимка реализована в ESE с помощью повторных операций чтения.
Структура базы данных ESE
Все данные в RTF-файле базы данных хранятся в сбалансированных деревьях (B+trees). Буква «B» в выражении «B+tree» означает «сбалансированное» (balanced). «Дерево» — это структура данных, подобная структуре папок в файловой системе, в которой корень является родителем элементов (страниц базы данных), которые, в свою очередь, являются родителями для других элементов. Сбалансированные деревья разработаны для обеспечения быстрого доступа к данным на диске. Поскольку чтение с диска и запись данных на диск выполняются намного медленнее, чем аналогичные операции в памяти, сбалансированное дерево разделено на страницы размером 8 КБ. Это позволяет ESE получать необходимые данные с помощью минимального количества операций дискового ввода-вывода. База данных ESE может содержать до 2^31 (2 в 31-й степени) страниц размером 8 КБ при общем максимальном размере базы данных, равном примерно 16 терабайт. В действительности размер базы данных ограничен только возможностями резервного копирования, восстановления и своевременного выполнения иных операций технического обслуживания базы данных (например операций автономной дефрагментации и исправления базы данных).
Страницы базы данных
Размер страницы в ESE определяется использующим его приложением. Например, ESE98 (серверы Exchange 2000 Server и Exchange Server 2003) использует страницы размером 4 КБ, в то время как ESENT (Active Directory) использует страницы размером 8 КБ. Каждая страница размером 4 или 8 КБ содержит указатели на другие страницы или фактические данные, хранящиеся в сбалансированном дереве. Страницы указателей и страницы данных хранятся в файле вперемешку.
Чтобы увеличить производительность до максимально возможного уровня, страницы кэшируются в буфер памяти на как можно более долгий период времени. Это снижает необходимость обращения к диску. Каждая страница начинается с заголовка размером 40 байт, который включает перечисленные ниже значения.
- pgnoThis Это значение указывает номер
страницы.
- DbtimeDirtied Это значение указывает
время последнего изменения страницы Dbtime.
- pgnoPrev Это значение содержит номер
смежной левой страницы на листе.
- pgnoNext Это значение содержит номер
смежной правой страницы на листе.
- ObjidFDP Это значение содержит
идентификатор объекта специальной страницы в базе данных, известной
как «отец страницы данных» (FDP), которая указывает, какому
сбалансированному дереву принадлежит эта страница. Страница FDP
используется в процессе восстановления.
- cbFree Это значение указывает
количество байт, доступных на странице.
- cbUncommittedFree Это значение
указывает количество доступных на странице незавершенных байт
(байт, которые свободны, но доступны для востребования при откате
транзакции).
- ibMicFree Это значение указывает
смещение страницы для следующего доступного байта на вершине
страницы.
Контрольная сумма ECC
Контрольная сумма кода коррекции ошибок (ECC) позволяет исправлять ошибки в одном бите в страницах базы данных (в файле EDB).
Контрольная сумма состоит из двух 32-разрядных контрольных сумм. Первая контрольная сумма представляет собой контрольную сумму XOR, в которой номер страницы используется в качестве начального значения при расчетах. Вторая 32-разрядная контрольная сумма представляет собой контрольную сумму ECC, которая позволяет исправлять однобитные ошибки на странице.
Согласованность базы данных и
ошибки -1018
При чтении страницы ESE проверяет флаг на странице, чтобы определить, соответствует ли формат контрольной суммы страницы текущему формату. Затем вычисляется соответствующая контрольная сумма. Если рассчитанная контрольная сумма не соответствует текущей контрольной сумме, ESE пытается исправить ошибку. Если ошибку не удается исправить автоматически, сервер Exchange Server 2007 сообщает об ошибке -1018.
Хранилище Exchange может само создавать ошибку -1018 при выполнении одного из указанных ниже действий.
- Хранилище Exchange создает страницу с неправильной контрольной
суммой.
- Хранилище Exchange создает страницу правильно, но указывает
операционной системе записать страницу в неверное
местоположение.
Если системный администратор сталкивается с ошибкой -1018, а при выполнении диагностических тестов оборудования сервера проблем не обнаруживается, администратор может сделать вывод о том, что причиной данной проблемы является сервер Exchange Server 2007, поскольку оборудование прошло диагностику.
Зачастую в ходе дополнительных исследований, проведенных корпорацией Майкрософт или производителями оборудования, обнаруживались трудноуловимые проблемы с оборудованием, микропрограммами или драйверами оборудования, которые являлись истинной причиной повреждения файла базы данных.
Обычные диагностические тесты могут обнаруживать не все временные сбои по ряду причин. Проблемы с микропрограммами или драйверами могут выходить за рамки возможностей диагностических программ. Диагностические тесты могут неадекватно имитировать продолжительное время работы или сложную нагрузку. Кроме того, запуск диагностического наблюдения или отладочного ведения журнала может изменить систему в достаточной степени, чтобы проблема не повторилась.
Простота и стабильность механизмов сервера Exchange Server 2007, создающих контрольные суммы и записывающих страницы в файл базы данных, гарантирует, что причиной ошибки -1018, скорей всего, является не сервер Exchange Server 2007. Механизмы контрольной суммы и обнаружения неправильных страниц просты и надежны, они фундаментально не изменялись с момента первого выпуска Exchange, за исключением незначительных изменений, внесенных для адаптации к изменению формата в новых версиях базы данных.
Контрольная сумма создается для страницы, которая готова к записи на диск, после того как в страницу записаны все данные, включаю номер страницы. После того как сервер Exchange Server 2007 добавляет к странице контрольную сумму, он указывает операционной системе Microsoft Windows Server записать страницу на диск, используя стандартные опубликованные API-интерфейсы Windows Server.
Контрольная сумма для страницы может быть создана правильно, но страница может быть записана в неверное местоположение на жестком диске. Это может быть вызвано временной ошибкой памяти, такой как «инверсия бита». Предположим, к примеру, что сервер Exchange Server 2007 создает новую версию страницы 70. Сама по себе страница не содержит ошибок, но копия номера страницы, используемая контроллером диска или операционной системой, случайным образом изменяется. Проблема может возникнуть, если 70 (1000110 в двоичном формате) меняется на 6 (000110 в двоичном формате) из-за нестабильности ячейки памяти. Контрольная сумма страницы все еще правильна, но местоположение страницы в базе данных теперь неверно. Обнаружив, что логический номер страницы не соответствует физическому местоположению страницы, сервер Exchange Server 2007 сообщает об ошибке -1018 для страницы.
Другая разновидность ошибки с нумерацией страниц (причиной которой является сервер Exchange Server 2007) может возникнуть при записи сервером Exchange Server 2007 неверного номера страницы в саму страницу. Но это приводит также к другим ошибкам, а не только к ошибке -1018. Если сервер Exchange Server записывает номер 71 на страницу 70, а затем записывает в страницу правильную контрольную сумму, страница записывается на место страницы 71 и успешно проходит проверку и номера страницы, и контрольной суммы.
Зачастую одна ошибка -1018 в базе данных сервера Exchange Server 2007 не приводит к остановке базы данных или приводит к симптомам, отличным от собственно ошибки -1018. Страница может находиться в редко используемой папке (например, в папке «Отправленные» или «Удаленные») или в редко открываемом вложении либо даже может быть пустой.
Хотя одиночная ошибка -1018, скорей всего, не приведет к большим потерям данных, множество ошибок -1018 являются поводом для беспокойства, поскольку ошибка -1018 является признаком того, что подсистема хранения данных не справилась с сохранением или загрузкой данных по крайней мере один раз. Хотя ошибка -1018 может оказаться случайной проблемой, которая никогда не повторится, более вероятно то, что эта ошибка является ранним признаком проблемы, которая со временем станет значительно серьезнее. Даже если первая ошибка -1018 произошла на пустой странице базы данных, неизвестно, какая страница окажется поврежденной в следующий раз. При повреждении критически важной глобальной таблицы база данных может не запуститься, а восстановление базы данных может оказаться частично или полностью неудачным.
После записи в журнал ошибки -1018 необходимо рассмотреть возможность приближающегося отказа или дополнительного случайного повреждения базы данных, пока не будет устранена главная причина.
Балансировка деревьев в базах
данных
Одной из основных функций ESE является постоянное поддержание дерева базы данных в сбалансированном состоянии. Процесс балансировки дерева завершен, когда все страницы либо разделены, либо объединены. Как показано на приведенном ниже рисунке, количество узлов на уровне корня дерева всегда равно количеству узлов на уровне листьев. Таким образом, дерево сбалансировано.
Сбалансированное дерево
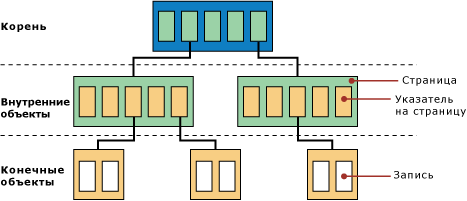
С точки зрения ESE таблица базы данных представляет собой набор сбалансированных деревьев. Каждая таблица состоит из сбалансированного дерева, содержащего данные, хотя множество сбалансированных деревьев дополнительного индекса также могут использоваться для обеспечения различных представлений данных. Если столбец или поле таблицы становится слишком большим для хранения в сбалансированном дереве, из него выделяется отдельное сбалансированное дерево, называемое деревом длинных значений.
Определение этих таблиц и соответствующих сбалансированных деревьев хранится в другом сбалансированном дереве, которое называется системным каталогом. Потеря системного каталога является серьезной проблемой. Поэтому ESE хранит две идентичных копии этого сбалансированного дерева в каждой базе данных.
Разделение
Когда страница становится почти заполненной, примерно половина данных помещается на дополнительную страницу, а на родительскую страницу дополнительной страницы помещается дополнительный ключ. Этот процесс выполняется только при незаполненной родительской странице. В случае заполнения родительской страницы она разделяется, а в родительскую страницу этой страницы добавляется указатель. В конечном счете каждая страница с указателями вплоть до корневого блока может потребовать разделения. В случае необходимости разделения корневого блока в дерево вставляется дополнительный уровень страниц. Фигурально выражаясь, дерево растет в высоту.
Объединение
Когда страница становится почти пустой, она объединяется с соседней страницей, указатели на родительской странице обновляются, и при необходимости процесс объединения продолжается. В конечном счете при объединении всех страниц с указателями вплоть до корневого блока высота дерева уменьшается. Чтобы добраться до листа (данных), ESE начинает поиск с корневого узла и переходит по указателям на страницы, пока не доберется до необходимого листа.
Развертывание
Структура сбалансированного дерева ESE отличается высокой степенью развертывания. Высокая степень развертывания означает, что ESE может добраться до любого блока данных в таблице размером 50 ГБ не более чем за 4 операции чтения с диска (три страницы с указателями и одна страница с данными). ESE хранит более 200 указателей на страницу в одной странице размером 4 КБ, что позволяет ESE использовать деревья с минимальным количеством уровней (также известные как низкорослые деревья). ESE также хранит ключ текущего дерева, что позволяет ESE быстро осуществлять поиск в текущем дереве. На приведенном выше рисунке показано дерево с тремя уровнями; дерево с четырьмя уровнями может хранить много гигабайт данных.
Индексы
Традиционное сбалансированное дерево индексируется только одним определенным способом. Оно использует один ключ, и данные необходимо загружать с помощью этого ключа. Например, записи в таблице сообщений индексируются по уникальному идентификатору сообщения, называемому идентификатором службы передачи сообщений. Однако пользователю может потребоваться просматривать данные в сообщениях в более удобном формате.
Индексы, точнее говоря, дополнительные индексы, используются для загрузки данных. Каждый дополнительный индекс представляет собой сбалансированное дерево, сопоставляющее вторичный ключ с первичным ключом. Это делает сбалансированные деревья небольшими по сравнению с индексируемыми ими данными.
Чтобы понять, каким образом используется дополнительный индекс, рассмотрим, что происходит, когда пользователь изменяет способ представления сообщений в папке сообщений. При изменении вида папки в Outlook таким образом, чтобы упорядочить сообщения по теме, а не по времени получения, Outlook обращается к хранилищу и ESE с запросом на создание нового дополнительного индекса для таблицы папки сообщений.
При изменении представлений в папке с большим количеством сообщений в первый раз наблюдается задержка. Если при этом внимательно следить за сервером, можно заметить небольшой всплеск активности диска. При повторном переключении к выбранному представлению индекс уже создан, и отклик будет намного быстрее.
Сбалансированные деревья дополнительного индекса служб банка данных Microsoft Exchange существуют в течение восьми дней. Если эти деревья не используются, служба банка данных Microsoft Exchange удаляет их в фоновом режиме.
Длинные значения
Столбец или запись в ESE не может занимать несколько страниц в сбалансированном дереве данных. Имеются значения (например PR_BODY, которое представляет текст сообщения), размер которых превышает размер страницы, равный 4 КБ. Эти значения называются длинными значениями. Для хранения таких длинных значений используется сбалансированное дерево длинных значений таблицы.
При поступлении в таблицу ESE блока данных, слишком большого, чтобы поместиться в сбалансированном дереве данных, он разделяется на страницы размером 4 КБ и сохраняется в отдельном сбалансированном дереве длинных значений таблицы. Запись в сбалансированном дереве данных содержит указатель на длинное значение. Этот указатель называется идентификатором длинного значения (LID) и означает, что запись имеет указатель на LID 256.
Формат записи
Набор сбалансированных деревьев представляет таблицу, а таблица является набором строк. Строка также называется записью. Запись состоит из нескольких столбцов. Максимальный размер записи, а, следовательно, максимальное количество столбцов в одной записи, определяется размером страницы базы данных за вычетом размера заголовка. Размер страницы в ESE равен 4 КБ. Таким образом, максимальный размер записи составляет приблизительно 4050 байт (4096 байт за вычетом размера заголовка страницы).
Типы данных столбцов
Каждое определение столбца должно указывать тип данных, хранящихся в столбце. ESE поддерживает типы данных, перечисленные в приведенной ниже таблице.
Типы данных столбцов расширенного обработчика хранилищ
| Типы данных столбцов | Описание |
|---|---|
|
Bit (бит) |
NULL, 0, или не-0 |
|
Unsigned Byte (беззнаковый байт) |
Однобайтовое беззнаковое целое число |
|
Short (короткое целое) |
Двухбайтовое целое число со знаком |
|
Unsigned Short (беззнаковое короткое целое) |
Двухбайтовое беззнаковое целое число |
|
Long (длинное целое) |
Четырехбайтовое целое число со знаком |
|
Unsigned Long (беззнаковое длинное целое) |
Четырехбайтовое беззнаковое целое число |
|
LongLong (очень длинное целое) |
Восьмибайтовое целое число со знаком |
|
Currency (валюта) |
Восьмибайтовое целое число со знаком |
|
IEEE Single (вещественное число IEEE одинарной точности) |
Четырехбайтовое число с плавающей запятой |
|
IEEE Double (вещественное число IEEE двойной точности) |
Восьмибайтовое число с плавающей запятой |
|
Date Time (дата и время) |
Восьмибайтовое число, содержащее дату и время (целая часть — дата, дробная — время) |
|
GUID |
16-байтовый уникальный идентификатор |
|
Binary (двоичная строка) |
Двоичная строка длиной <= 255 |
|
Text (текстовый) |
Строка ANSI или Юникод длиной <= 255 байт |
|
Long Binary (длинная двоичная строка) |
Длинная двоичная строка длиной < 2 ГБ |
|
Long Text (длинный текст) |
Строка ANSI или Юникод длиной < 2 ГБ |
Типы данных столбцов делятся на две категории. В первую категорию попадают фиксированные и переменные столбцы. Во вторую категорию попадают прикрепленные столбцы. Каждый столбец определяется как структура FIELD размером 16 байт плюс размер имени столбца.
При создании таблицы в базе данных ESE таблица определяется через массив структур FIELD. Этот массив определяет отдельные столбцы в таблице. В данном массиве каждый столбец представлен значением индекса, называемом идентификатором столбца. Этот массив подобен обычному массиву, в котором доступ к элементам массива осуществляется по номеру, например массив[0], массив[1] и т.д. Доступ к столбцам осуществляется быстро по идентификатору, но поиск по имени столбца требует линейного сканирования массива структур FIELD.
Фиксированные и переменные
столбцы
Фиксированные столбцы содержат данные фиксированной длины. Каждая запись занимает заданный объем, даже если значение не указано. Типы данных с идентификаторами от 1 до 10 можно определить как фиксированные столбцы. В каждой таблице можно определить до 126 фиксированных столбцов (с идентификаторами столбца от 1 до 127).
Переменные столбцы могут содержать до 256 байт данных. Массив смещений хранится в записи с самым большим установленным значением переменного столбца. Для каждого столбца требуется два байта. Типы данных с идентификаторами от 10 до 11 можно определить как переменные столбцы. В каждой таблице можно определить до 127 переменных столбцов (с идентификаторами столбца от 128 до 256).
Прикрепленные столбцы
Прикрепленные столбцы определяются в ESE как редко используемые столбцы или столбцы, часто используемые в одной записи. Неопределенный прикрепленный столбец не приводит к дополнительным расходам дискового пространства. Прикрепленный столбец может несколько раз использоваться в одной записи. Если прикрепленный столбец представлен в дополнительном индексе, индексируется каждое использование столбца.
Прикрепленные столбцы могут содержать неограниченный объем данных переменной длины. Идентификатор столбца и длина хранятся вместе с данными. В качестве прикрепленных столбцов можно определять все типы данных. В каждой таблице можно определить до 64 993 прикрепленных столбцов.