

Topic Last Modified: 2013-02-22
The Centralized Logging Service is designed to provide a means for controlled collection of data—with a broad or narrow scope. You can collect data from all servers in the deployment concurrently, define specific elements to trace, set trace flags and return search results from a single computer or an aggregation of all data from all servers. The Centralized Logging Service runs on all servers in your deployment. The architecture of the Centralized Logging Service is comprised of the following agents and services:
-
Centralized Logging Service Agent ClsAgent.exe is the service executable that communicates with the controller and receives the commands that the controller is issued by the administrator. The agent is run as a service on each Lync Server computer. When the agent receives a command, it executes the command, sends messages to the defined components for tracing, and writes the trace logs to disk. It also reads the trace logs for its computer and sends the trace data back to the controller when requested. The ClsAgent listens for commands on the following ports: TCP 50001, TCP 50002, and TCP 50003.
-
Centralized Logging Service Controller ClsControllerLib.dll is the command execution engine for the Lync Server Management Shell and for ClsController.exe. CLSControllerLib.dll sends Start, Stop, Flush, and Search commands to the ClsAgent. When search commands are sent, the resulting logs are returned to the ClsControllerLib.dll and aggregated. The controller is responsible for sending commands to the agent, receiving the status of those commands and managing the search log file data as it is returned from all agents on any computer in the search scope, and aggregating the log data into a meaningful and ordered output set. The information in the following topics is focused on using the Lync Server Management Shell. ClsController.exe is limited to a subset of the features and functions that are available in the Lync Server Management Shell. Help for ClsController.exe is available at the command line by typing
ClsControllerin the default directory C:\Program Files\Common Files\Microsoft Lync Server 2013\ClsAgent.
ClsController communications to ClsAgent
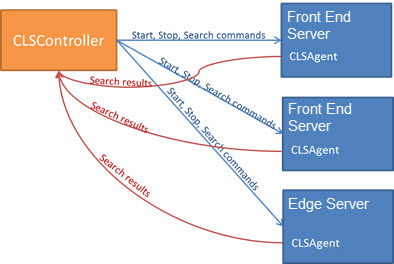
You issue commands using the Windows Server command-line interface or using the Lync Server Management Shell. The commands are executed on the computer you are logged in to and sent to the ClsAgent locally or to the other computers and pools in your deployment.
ClsAgent maintains an index file of all .CACHE files that it has on the local machine. ClsAgent allocates them so that they are evenly distributed across volumes defined by the option CacheFileLocalFolders, never consuming more than 80% of each volume (that is, the local cache location and the percentage is configurable using the Set-CsClsConfiguration cmdlet). ClsAgent is also responsible for aging old cached event trace log (.etl) files off the local machine. After two weeks (that is, the timeframe is configurable using the Set-CsClsConfiguration cmdlet) these files are copied to a file share and deleted from the local computer. For details, see Set-CsClsConfiguration. When a search request is received, the search criteria is used to select the set of cached .etl files to perform the search based on the values in the index maintained by the agent.
 Note: Note: |
|---|
| Files that are moved to the file share from the local computer can be searched by ClsAgent. Once ClsAgent moves the files to the file share, the aging and removal of files is not maintained by ClsAgent. You should define an administrative task to monitor the size of the files in the file share and delete them or archive them. |
The resulting log files can be read and analyzed using a variety of tools, including Snooper.exe and any tool that can read a text file, such as Notepad.exe. Snooper.exe is part of the Lync Server 2013 Debug Tools and is available as a Web download from http://go.microsoft.com/fwlink/?LinkId=285257.
Like OCSLogger, the Centralized Logging Service has several components to trace against, and provides options to select flags, such as TF_COMPONENT and TF_DIAG. Centralized Logging Service also retains the logging level options of OCSLogger.
The most important advantage to using the Lync Server Management Shell over the command-line ClsController is that you can configure and define new scenarios using selected providers that target the problem space, custom flags, and logging levels. The scenarios available to ClsController are limited to those that are defined for the executable.
In previous versions, OCSLogger.exe was provided to enable administrators and support personnel to collect trace files from computers in the deployment. OCSLogger, for all of its strengths, had a shortcoming. You could only collect logs on one computer at a given time. You could log on to multiple computers by using separate copies of OCSLogger, but you ended up with multiple logs and no easy way to aggregate the results.
When a user requests a log search, the ClsController determines which machines to send the request to (that is, based on the scenarios selected). It also determines whether the search needs to be sent to the file share where the saved .etl files are located. When the search results are returned to the ClsController, the controller merges the results into a single time-ordered result set that is presented to the user. Users can save the search results to their local machine for further analysis.
When you start a logging session, you specify scenarios that are relative to the problem that you are trying to resolve. You can have two scenarios running at any time. One of these two scenarios should be the AlwaysOn scenario. As the name implies, it should always be running in your deployment, collecting information on all computers, pools, and components.
 Important: Important: |
|---|
| By default, the AlwaysOn scenario is not running in your deployment. You must explicitly start the scenario. Once started, it will continue to run until explicitly stopped, and the running state will persist through reboots of the computers. For details on starting and stopping scenarios, see Using Start for the Centralized Logging Service to Capture Logs and Using Stop for the Centralized Logging Service. |
When a problem occurs, start a second scenario that relates to the problem reported. Reproduce the problem, and stop the logging for the second scenario. Begin your log searches relative to the problem reported. The aggregated collection of logs produces a log file that contains trace messages from all computers in your site or global scope of your deployment. If the search returns more data than you can feasibly analyze (typically known as a signal-to-noise ratio, where the noise is too high), you run another search with narrower parameters. At this point, you can begin to notice patterns that show up and can help you get a clearer focus on the problem. Ultimately, after you perform a couple of refined searches you can find data that is relevant to the problem and figure out the root cause.
 Tip: Tip: |
|---|
| When presented with a problem scenario in Lync Server, start by
asking yourself “What do I already know about the problem?” If you
quantify the problem boundaries, you can eliminate a large part of
the operational entities in Lync Server. Consider an example scenario where you know that users are not getting current results when looking for a contact. There is no point in looking for problems in the media components, Enterprise Voice, conferencing, and a number of other components. What you may not know is where the problem actually is: on the client, or is this a server-side problem? Contacts are collected from Active Directory by the User Replicator and delivered to the client by way of the Address Book Server (ABServer). The ABServer gets its updates from the RTC database (where User Replicator wrote them) and collects them into address book files, by default – 1:30 AM. The Lync Server clients retrieve the new address book on a randomized schedule. Because you know how the process works, you can reduce your search for the potential cause to an issue related to data being collected from Active Directory by the User Replicator, the ABServer not retrieving and creating the address book files, or the clients not downloading the address book file. |